Có một chuyện rất lạ: càng sống trong thời đại dữ liệu, chúng ta lại càng dễ bị lạc trong dữ liệu.
Bạn mở Google tìm tên một diễn viên. Chỉ vài giây sau, màn hình hiện ra một khung thông tin: tên, ngày sinh, phim nổi bật, người liên quan, đường dẫn chính thức. Bạn không click vào đâu cả – Google tự biết bạn đang hỏi về người đó, và trả lời thẳng.
Chuyển sang Netflix, một danh sách phim "dành riêng cho bạn" hiện ra – không chỉ dựa trên lịch sử xem, mà còn dựa trên mối liên hệ giữa phim, diễn viên, thể loại, chủ đề. Hay khi bạn hỏi trợ lý ảo "ai là CEO của Apple hiện tại?" – hệ thống không tìm kiếm từ khóa mù mờ, mà tách ra được: Apple là công ty, CEO là vai trò, rồi tra vào một kho tri thức để lấy đúng câu trả lời.

Nhìn bên ngoài, mọi thứ có vẻ như phép màu. Nhưng phía sau những trải nghiệm rất đời thường đó là một câu hỏi nền tảng: Làm sao máy tính biết các sự vật trong thế giới liên quan với nhau như thế nào?
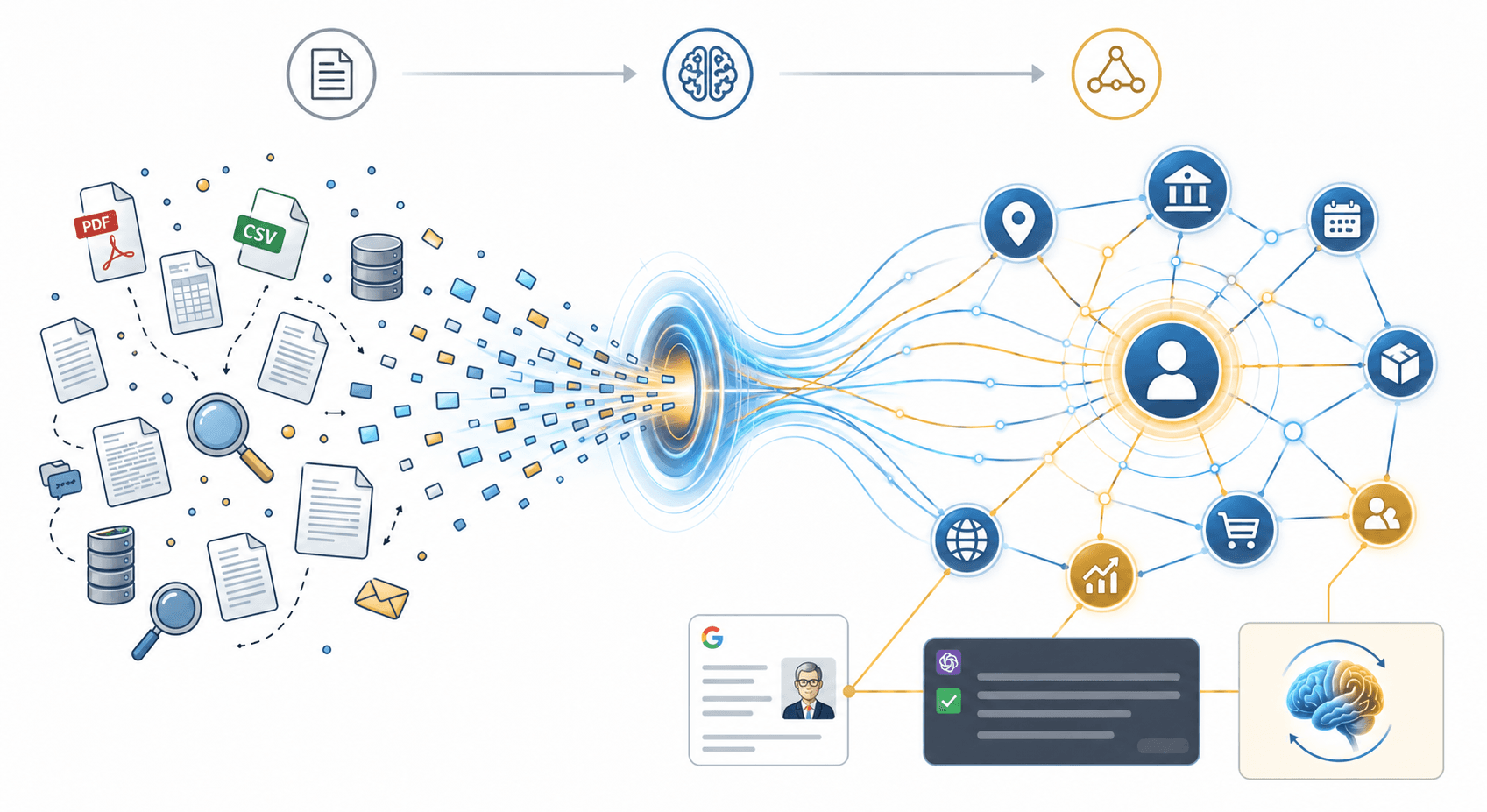
Một trong những ý tưởng quan trọng đứng sau khả năng đó là Đồ thị tri thức (Knowledge Graph): cách biểu diễn tri thức không chỉ bằng từng mẩu dữ liệu riêng lẻ, mà bằng mạng lưới các thực thể và quan hệ giữa chúng.
1. Vì sao dữ liệu cần được nối lại với nhau?
Hãy thử nhìn quanh một ngày bình thường.
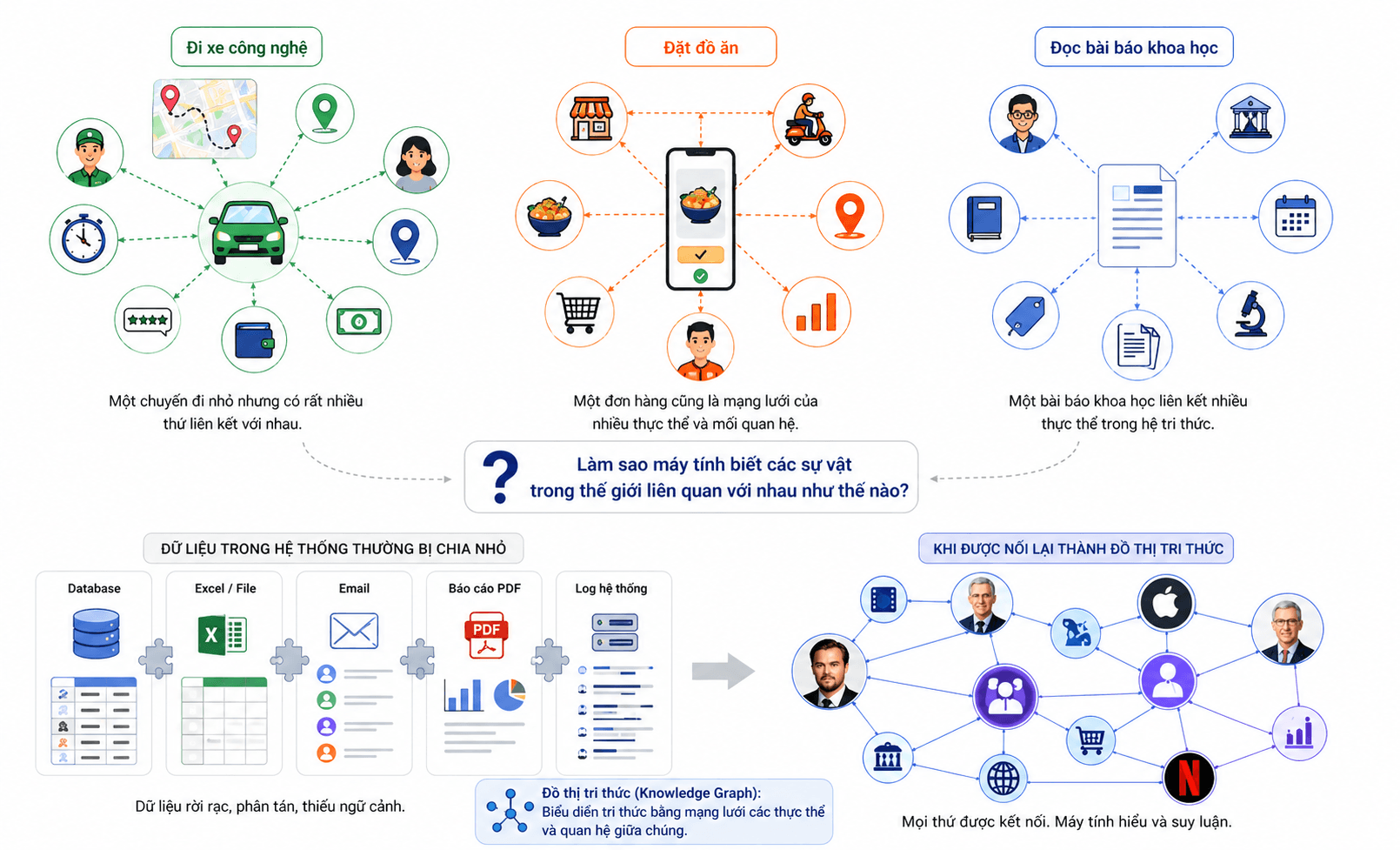
Bạn đi làm bằng xe công nghệ. Một chuyến đi nhỏ đã có rất nhiều thứ liên kết: tài xế, hành khách, điểm đón, điểm đến, tuyến đường, thời gian, giá tiền, phương thức thanh toán, đánh giá sau chuyến đi.
Bạn đặt đồ ăn. Một đơn hàng cũng không đơn giản: món ăn thuộc nhà hàng nào, nhà hàng ở đâu, shipper nào giao, khách hàng từng đặt món gì, món nào hay được mua chung, khung giờ nào đông khách.
Bạn đọc một bài báo khoa học. Bài báo đó có tác giả, tổ chức, tạp chí, năm công bố, chủ đề, tài trợ, và những bài khác trích dẫn nó.
Thế giới thật là như vậy: người nối với người, người nối với tổ chức, tổ chức nối với địa điểm, địa điểm nối với sự kiện, sự kiện nối với tri thức khác.
Nhưng dữ liệu trong hệ thống máy tính lại thường tồn tại trong những ốc đảo riêng biệt – mỗi hệ thống, mỗi phòng ban, mỗi công cụ giữ một phần, theo một cách riêng, không nói chuyện được với nhau. Mỗi nơi giữ một mảnh của bức tranh. Nhưng nếu các mảnh không biết liên kết với nhau, ta chỉ có nhiều dữ liệu, chứ chưa chắc có nhiều hiểu biết.
2. Khi những mảnh dữ liệu bắt đầu biết liên kết
Máy tính không tự nhiên "hiểu" quan hệ giữa các sự vật. Thử hình dung thế này: bạn gõ vào ô tìm kiếm "Tim Cook CEO Apple". Máy thấy ba cụm ký tự đứng cạnh nhau. Nó không tự biết Tim Cook là người, Apple là công ty, hay "CEO" đang mô tả quan hệ giữa hai thực thể đó. Nếu không được chỉ dẫn, nó chỉ match từ khóa – giống như tra từ điển theo vần, không phải theo nghĩa.
Những câu hỏi quan trọng trong thực tế thường không hỏi "dòng dữ liệu này nằm ở đâu?" – chúng hỏi:
- Cái gì liên quan đến cái gì?
- Sự kiện này bắt nguồn từ đâu?
- Nếu một mắt xích thay đổi, những thứ nào bị ảnh hưởng?
Để máy tính trả lời được những câu hỏi đó, chúng ta phải chỉ cho nó: thực thể là ai/cái gì, quan hệ giữa chúng là gì, và những quan hệ này đan vào nhau như một mạng lưới.
Đó là lý do nhiều tổ chức lớn đầu tư vào các dạng Đồ thị tri thức hoặc hệ thống tri thức có cấu trúc riêng, từ công cụ tìm kiếm, thương mại điện tử, mạng xã hội cho đến nghiên cứu học thuật. Khi Google giới thiệu Đồ thị tri thức năm 2012, hệ thống đã chứa hơn 500 triệu đối tượng và hơn 3,5 tỷ mối quan hệ. Đến năm 2020, con số đó đã tăng lên hơn 500 tỷ facts về khoảng 5 tỷ entities.
3. Từ những mảnh rời rạc đến bức tranh tri thức
Thử một bài tập nhỏ.
Lấy tờ giấy trắng:
- Viết tên bạn ở giữa.
- Vẽ xung quanh những vòng tròn: bạn bè, người thân, đồng nghiệp.
- Từ mỗi người, vẽ thêm: nơi họ sống, công ty họ làm, sở thích chung.
Về trực giác, bạn vừa vẽ một Đồ thị tri thức thu nhỏ: không nhìn thế giới như một danh sách, mà như một mạng lưới các điểm và mối liên hệ.
Các doanh nghiệp làm đúng điều đó – nhưng ở quy mô lớn hơn, và cho những mục đích ít ngờ tới hơn.
Trong y tế, Đồ thị kết nối triệu chứng – bệnh – thuốc – kết quả xét nghiệm – nghiên cứu lâm sàng. Khi bác sĩ nhập một tổ hợp triệu chứng hiếm gặp, hệ thống có thể gợi ý các chẩn đoán mà ngay cả bác sĩ nhiều kinh nghiệm cũng dễ bỏ sót.
Trong tài chính, Đồ thị kết nối người – tài khoản – giao dịch – địa chỉ – thiết bị. Khi một kẻ gian dùng nhiều danh tính để rửa tiền, nhìn từng bảng dữ liệu rời rạc sẽ không thấy gì – nhưng nhìn vào Đồ thị, các nút liên kết với nhau lộ ra ngay.
Trong khoa học, OpenAlex mô tả hệ thống nghiên cứu học thuật như một Đồ thị gồm các thực thể liên kết: works, authors, institutions, sources, funders và topics. Thay vì chỉ lưu bài báo, Đồ thị giúp trả lời: ai đang nghiên cứu chủ đề này, nhóm nào hợp tác với nhóm nào, một lĩnh vực đang phát triển theo hướng nào.
Trong thương mại điện tử, Amazon từng mô tả việc xây dựng một commonsense Đồ thị tri thức để hỗ trợ gợi ý sản phẩm – không chỉ nối "sản phẩm A mua cùng sản phẩm B", mà còn nối sản phẩm với lý do, bối cảnh, nhu cầu, tình huống sử dụng. Ví dụ, với truy vấn "shoes for pregnant women", hệ thống suy luận được rằng phụ nữ mang thai có thể cần giày chống trượt.
Trong cybersecurity, một đội an toàn thông tin có thể đang theo dõi hàng nghìn cảnh báo mỗi ngày: địa chỉ IP, tài khoản, máy chủ, lỗ hổng, phần mềm độc hại, kỹ thuật tấn công. Nhìn từng cảnh báo riêng lẻ, rất khó biết đâu là mối đe dọa thật sự, đâu là nhiễu.
Nhưng khi các mảnh đó được nối vào một Đồ thị – IP này đã từng kết nối đến máy chủ nào, tài khoản nào đăng nhập từ địa chỉ lạ, lỗ hổng nào đang bị khai thác theo kỹ thuật nào – bức tranh tấn công bắt đầu hiện ra.
MITRE ATT&CK là một ví dụ thực tế: đây là một knowledge base toàn cầu về tactics và techniques của các nhóm tấn công, dựa trên quan sát thực tế, được dùng làm nền tảng cho threat modeling trong doanh nghiệp, chính phủ và cộng đồng bảo mật. Thay vì mỗi tổ chức tự ghi chép riêng, MITRE ATT&CK tạo ra một ngôn ngữ chung – một Đồ thị chung – để cộng đồng bảo mật chia sẻ và đối chiếu tri thức về kẻ tấn công.
4. Vì sao AI hiện nay càng cần Đồ thị tri thức?
Các mô hình ngôn ngữ lớn có thể viết, tóm tắt, dịch, giải thích và trò chuyện rất tự nhiên. Nhưng một mô hình ngôn ngữ không tự động đảm bảo rằng mọi thông tin nó đưa ra đều đúng, có nguồn, có cấu trúc, và nhất quán theo thời gian.
Đồ thị tri thức không thay thế AI – nhưng nó bổ sung cho AI ở một điểm rất quan trọng: tri thức có cấu trúc và có quan hệ rõ ràng.
Một mô hình AI có thể trả lời rất trôi chảy. Một Đồ thị tri thức có thể giúp kiểm tra: thực thể nào, quan hệ nào, nguồn nào, ngữ cảnh nào. Đó cũng là lý do những chủ đề như GraphRAG đang được nhắc đến nhiều – thay vì chỉ tìm các đoạn văn bản giống câu hỏi, hệ thống có thể lần theo các thực thể và quan hệ để lấy đúng ngữ cảnh hơn trước khi trả lời.
Nếu ví mô hình AI là bộ não tính toán – giỏi dự đoán, phân loại – thì Đồ thị tri thức là bộ não tri thức – giỏi hiểu "ai/cái gì", "liên hệ thế nào". Hai thứ kết hợp với nhau mới tạo ra những hệ thống thực sự thông minh.
5. Chuỗi bài này dành cho ai?
Chuỗi bài này dành cho người từng nghe đến Đồ thị tri thức nhưng chưa biết bắt đầu từ đâu.
Dành cho người làm dữ liệu muốn hiểu vì sao bảng dữ liệu đôi khi chưa đủ. Dành cho người làm AI muốn hiểu vì sao mô hình ngôn ngữ vẫn cần tri thức có cấu trúc. Dành cho người làm y tế, tài chính, thương mại điện tử, nghiên cứu, an toàn thông tin – những nơi dữ liệu không đứng một mình.
Bạn không cần biết trước Lý thuyết đồ thị, SPARQL, RDF hay ontology. Không có công thức toán cao cấp. Không ký hiệu khó đọc. Thay vào đó là trực giác, ví dụ đời sống, và case thật từ nhiều ngành.
Ta sẽ bắt đầu từ câu hỏi rất con người: mọi thứ đang liên quan đến nhau như thế nào?
Kết: giá trị không nằm ở từng mảnh, mà ở cách chúng được nối lại
Dữ liệu giống như những mảnh ghép. Một mảnh cho ta biết một điều. Nhiều mảnh cho ta biết nhiều điều. Nhưng chỉ khi các mảnh được nối đúng, ta mới nhìn thấy bức tranh.
Đồ thị tri thức bắt đầu từ một ý tưởng đơn giản nhưng mạnh: muốn hiểu thế giới, đừng chỉ nhìn từng điểm riêng lẻ – hãy nhìn vào các mối liên kết giữa chúng.
Mỗi lần bạn Google tên một người nổi tiếng và thấy cái ô thông tin hiện ra bên phải màn hình – bạn có bao giờ tự hỏi cái ô đó được "nhồi" dữ liệu như thế nào không?
Đó chính xác là điều Bài 1 sẽ mổ xẻ.