Bài viết & Thông báo
Cập nhật bài viết và thông báo mới nhất từ khoa An toàn Thông tin
5 kết quả#AI Agent
 blogs
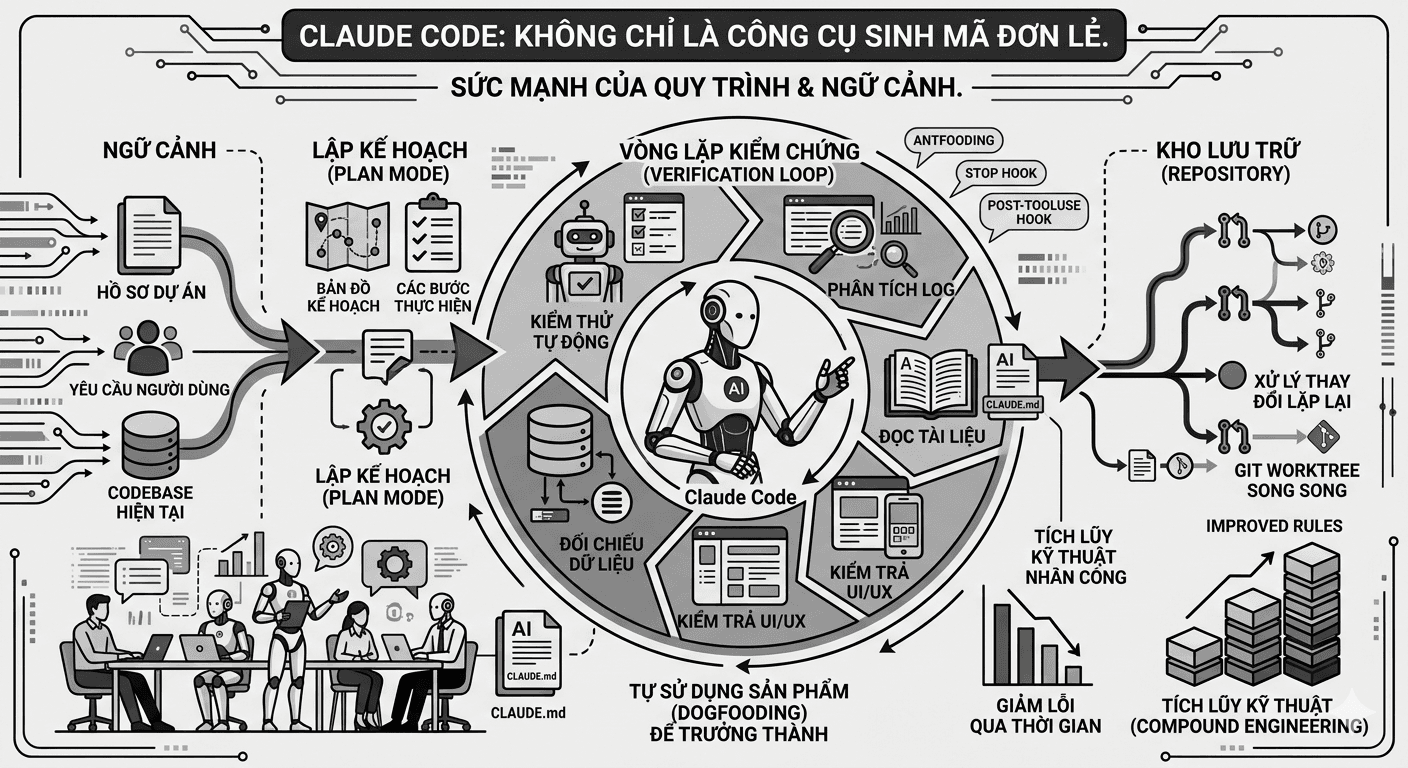
blogsClaude Code best practice (04/2026)
Bài viết trình bày các thực hành quan trọng khi sử dụng Claude Code trong phát triển phần mềm, tập trung vào cách giao việc rõ ràng, lập kế hoạch trước khi triển khai, thiết lập verification loop, quản lý CLAUDE.md, sử dụng Git worktree, subagent, hook và permission để biến AI coding agent thành một phần có kiểm soát trong quy trình kỹ thuật. Nội dung nhấn mạnh rằng hiệu quả của Claude Code không nằm ở việc sinh mã nhanh, mà ở khả năng tổ chức môi trường làm việc có ngữ cảnh, có kiểm chứng và có khả năng tích lũy tri thức dự án theo thời gian.
 blogs
blogsSecure code review cho code do AI agent tạo ra (updated to 2026)
Code do AI agent tạo ra cần được review như một phần của Secure SDLC, không chỉ như thao tác đọc diff trong pull request. Quy trình review phải kiểm tra đồng thời logic bảo mật, tác động thiết kế, side effects ngoài phạm vi task, test bảo mật, CI/CD gate và bằng chứng vận hành. Các case study cho thấy từng thay đổi sai của agent có thể được ánh xạ trực tiếp tới checklist, giúp reviewer phát hiện lỗi có hệ thống trước khi merge hoặc deploy.
 blogs
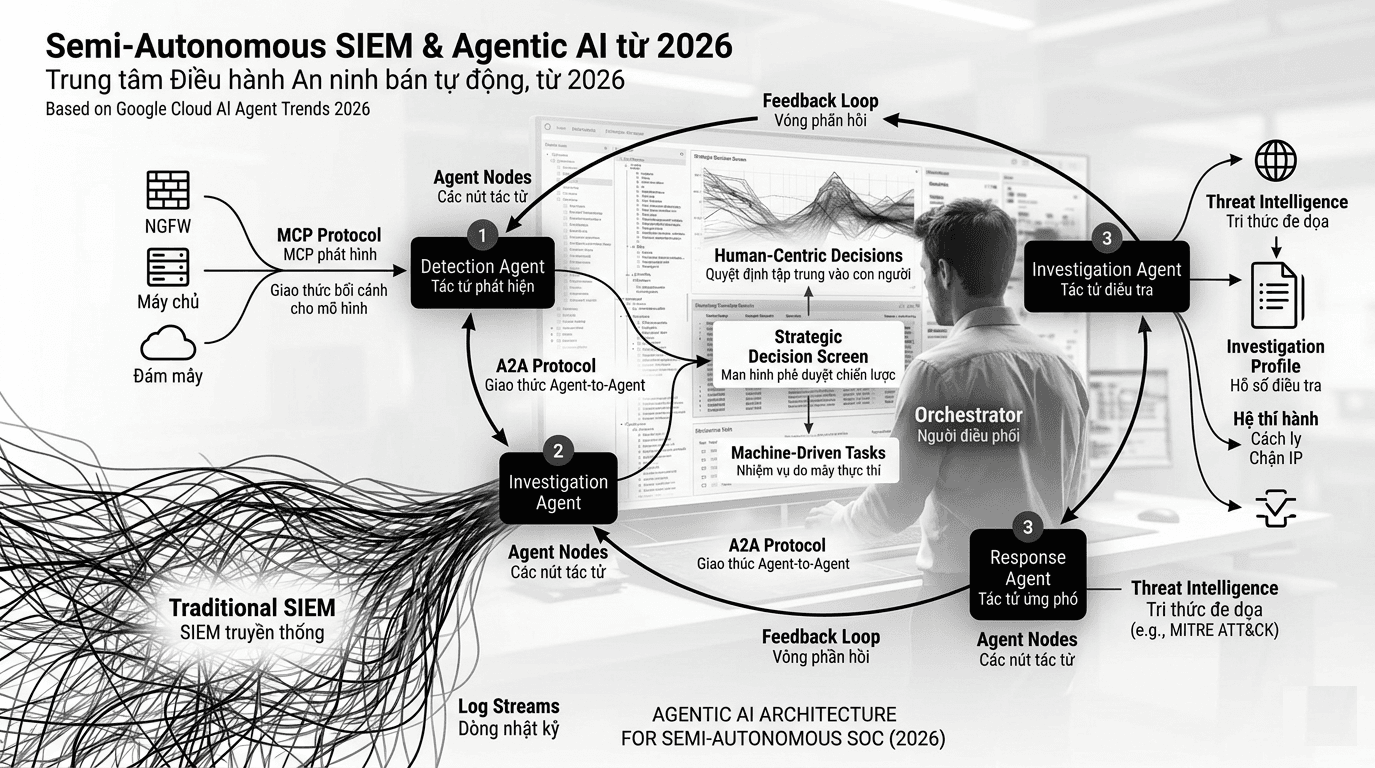
blogsTừ SIEM đến SOC bán tự động: Khi Agentic AI thay đổi cách vận hành an ninh mạng
SIEM vẫn là nền tảng quan trọng trong vận hành an ninh mạng, nhưng giới hạn của nó nằm ở khoảng trống giữa phát hiện, điều tra và ứng phó. Khi khối lượng cảnh báo tăng mạnh và attacker bắt đầu khai thác AI, mô hình SOC truyền thống cần được mở rộng bằng các tác tử AI có khả năng phân loại, điều tra và hỗ trợ phản ứng tự động trong phạm vi kiểm soát. Bài viết phân tích vai trò của SIEM, các sai lầm triển khai thường gặp, kiến trúc SOC bán tự động, MCP, A2A và những điều kiện cần có để tự động hóa an ninh mạng một cách an toàn.
 blogs
blogsChuyện Gì Xảy Ra Khi Hệ Thống Trí Tuệ Nhân Tạo Không Có Khóa Cửa?
Hạ tầng AI đang được triển khai nhanh hơn nhiều so với tốc độ mà cộng đồng bảo mật có thể theo kịp. Các đội ngũ kỹ thuật tập trung vào việc làm cho AI hoạt động, làm cho sản phẩm ra đời nhanh, và phần bảo vệ bị bỏ lại phía sau. Kẻ tấn công nhận ra điều này sớm hơn nhiều người nghĩ. Nếu tổ chức bạn đang dùng MCP trong môi trường thực tế, đây là thời điểm để kiểm tra lại cấu hình. Không phải vì ai đó đang nhắm vào bạn cụ thể, mà vì các scanner tự động không cần nhắm vào ai cụ thể. Chúng quét tất cả, và chúng không nghỉ.
 blogs
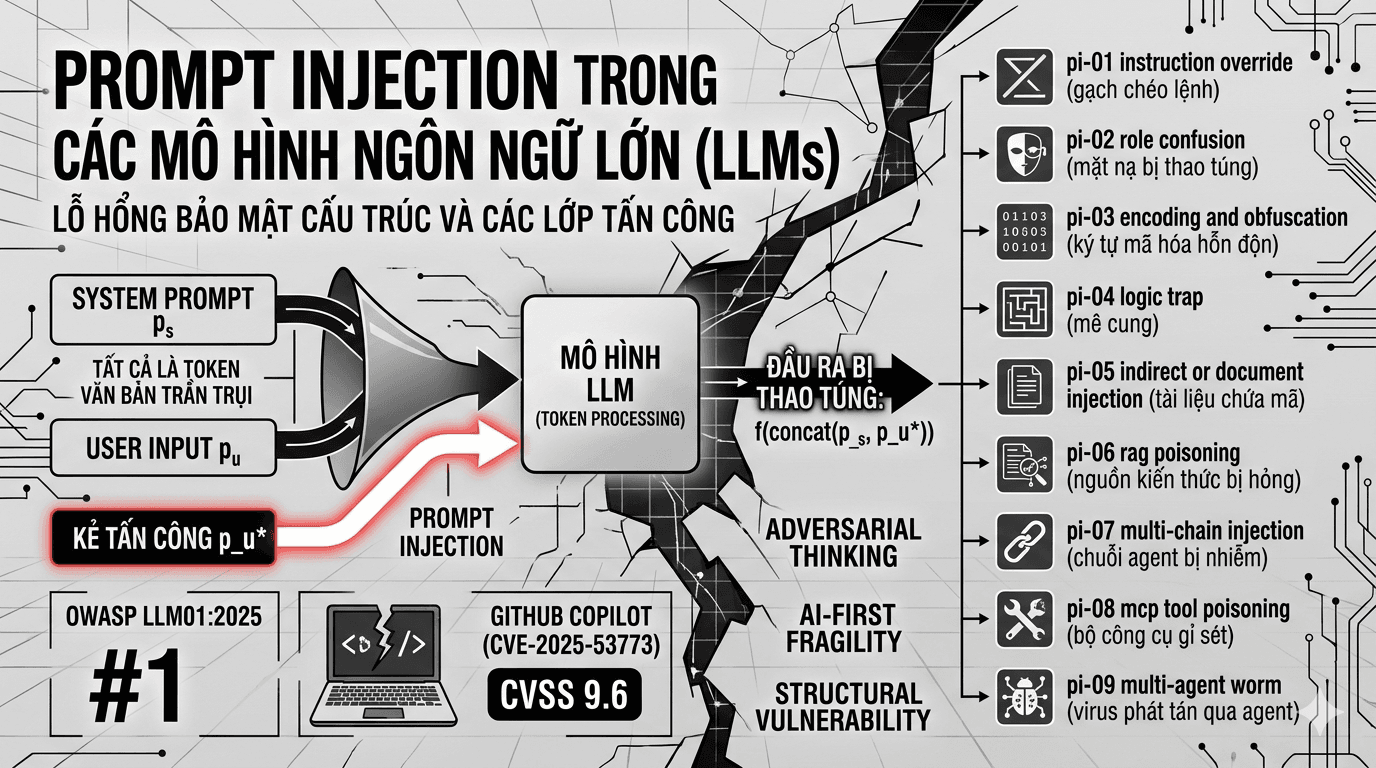
blogsTấn công Prompt Injection vào các Mô hình Ngôn ngữ Lớn
Tấn công Prompt Injection (PI) vào các Mô hình Ngôn ngữ Lớn đã được OWASP xếp hạng là lỗ hổng bảo mật số một (LLM01:2025) trong danh sách OWASP Top 10 cho Ứng dụng LLM năm 2025. Phân tích cho thấy rằng mặc dù các cơ chế phòng thủ hiện tại ngày càng tinh vi, các cuộc tấn công thích ứng (adaptive attacks) vẫn có thể vượt qua hơn 90% các biện pháp phòng thủ được công bố. Điều này phản ánh một nghịch lý kiến trúc cơ bản: LLM không có khả năng phân biệt "dữ liệu" và "lệnh" ở cấp độ cú pháp tất cả đều là văn bản thuần túy.