Phần 1: Mở Đầu
AI cần được nhìn như một năng lực phát triển xã hội
Trí tuệ nhân tạo (Artificial Intelligence) không nên được hiểu như một công nghệ đơn lẻ. AI là một năng lực mới của xã hội số, giúp con người mở rộng khả năng quan sát, phân tích, dự đoán, tự động hóa và sáng tạo. Khi AI được đặt trong hoạt động của doanh nghiệp, trường học, bệnh viện, nhà máy hoặc cơ quan nhà nước, nó không chỉ thay đổi cách một phần mềm hoạt động. Nó thay đổi cách tổ chức hiểu dữ liệu, thiết kế quy trình, phục vụ con người và tạo ra giá trị mới.
Điểm quan trọng của một bài giới thiệu AI không nằm ở việc liệt kê thật nhiều công cụ. Công cụ thay đổi rất nhanh. Điều cần nắm là cấu trúc tư duy phía sau AI. Tại sao AI xuất hiện mạnh trong giai đoạn hiện nay. AI khác gì với phần mềm thông thường. Machine Learning hoạt động theo cơ chế nào. Deep Learning giải quyết điểm yếu gì của Machine Learning truyền thống. Generative AI và Large Language Model vì sao tạo ra làn sóng mới. AI Agent và Agentic AI vì sao đang trở thành hướng triển khai đáng chú ý trong tổ chức.
Bài luận này được trình bày lại dựa trên bài thuyết trình giới thiệu về AI của tiến sĩ Ngô Tùng Sơn dành cho các cán bộ quản lý của Denso Việt Nam.
AI trong dòng chảy của các cuộc cách mạng công nghiệp
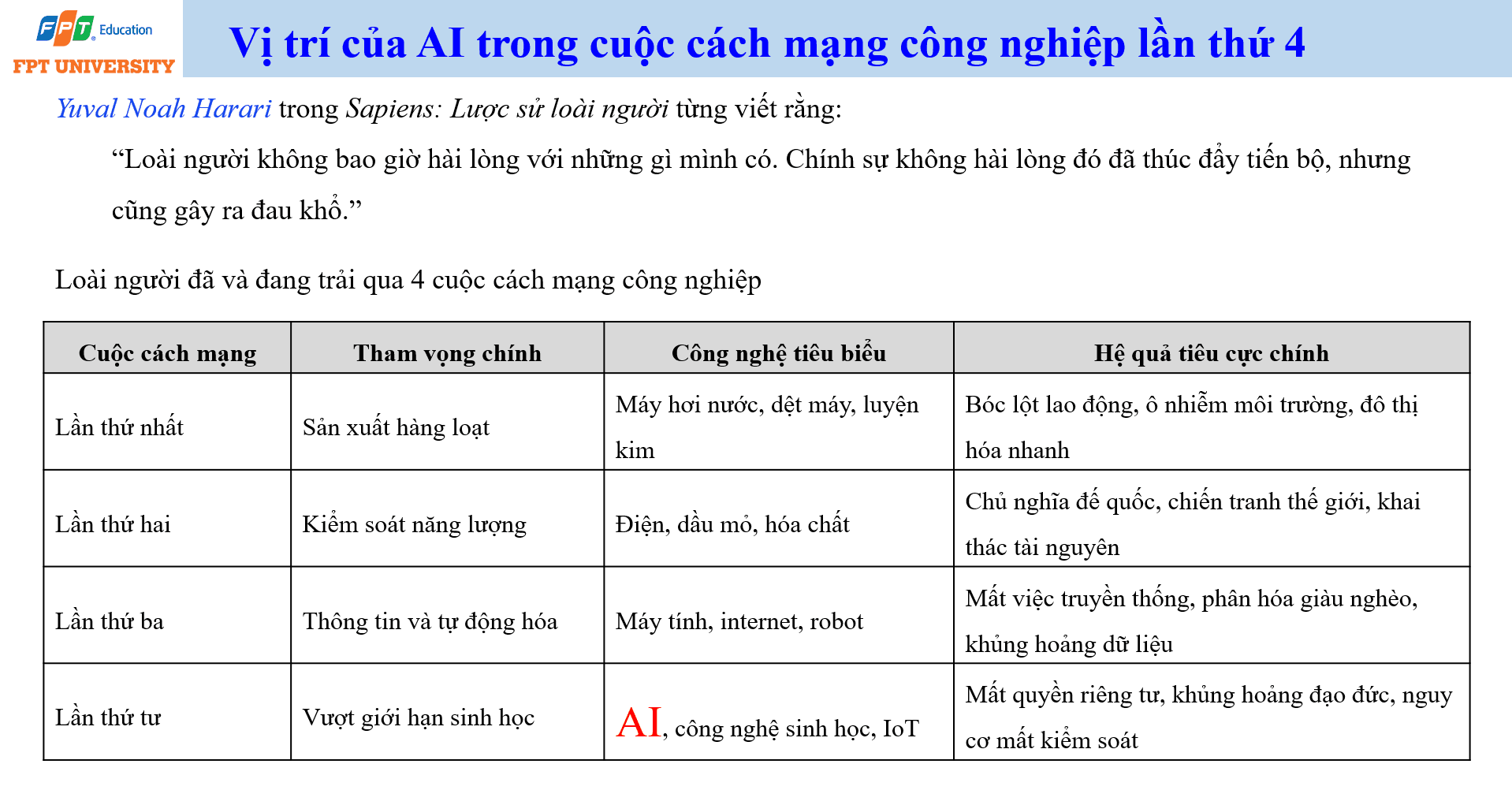
Để hiểu đúng AI, cần đặt nó vào dòng chảy dài hơn của các cuộc cách mạng công nghiệp. Yuval Noah Harari trong cuốn sách Sapiens (lược sử loài người) nêu một ý đáng chú ý: loài người không bao giờ hài lòng với những gì mình có. Chính sự không hài lòng đó thúc đẩy tiến bộ, nhưng cũng có thể tạo ra đau khổ. Nhận định này giúp mở ra một cách nhìn cân bằng về công nghệ. Công nghệ không tự động tạo ra điều tốt đẹp. Công nghệ mở rộng năng lực của con người. Năng lực đó có thể được dùng để cải thiện đời sống, nhưng cũng có thể tạo ra bất bình đẳng, rủi ro đạo đức và mất kiểm soát nếu thiếu quản trị.
Cuộc cách mạng công nghiệp lần thứ nhất gắn với máy hơi nước, dệt máy và luyện kim. Tham vọng chính của giai đoạn này là sản xuất hàng loạt. Kết quả tích cực là năng suất tăng mạnh, hàng hóa được sản xuất nhanh hơn và rẻ hơn. Nhưng hệ quả tiêu cực cũng rất rõ, gồm bóc lột lao động, ô nhiễm môi trường và đô thị hóa nhanh. Lần thứ hai gắn với điện, dầu mỏ và hóa chất. Tham vọng chính là kiểm soát năng lượng. Nhờ điện và các ngành công nghiệp mới, xã hội hiện đại hình thành nhanh hơn, nhưng cũng kéo theo chủ nghĩa đế quốc, chiến tranh thế giới và khai thác tài nguyên ở quy mô lớn.
Cuộc cách mạng công nghiệp lần thứ ba gắn với máy tính, Internet và robot. Tham vọng trung tâm là thông tin và tự động hóa. Con người bắt đầu số hóa quy trình, lưu trữ dữ liệu, kết nối hệ thống và dùng phần mềm để thay thế một phần lao động lặp lại. Hệ quả tiêu cực của giai đoạn này là mất việc truyền thống, phân hóa giàu nghèo và khủng hoảng dữ liệu. Đến cuộc cách mạng công nghiệp lần thứ tư, AI, công nghệ sinh học (biotechnology) và Internet vạn vật (Internet of Things) trở thành các công nghệ tiêu biểu. Tham vọng không chỉ là tăng năng suất, mà còn là vượt qua một số giới hạn sinh học của con người trong nhận thức, dự đoán, điều khiển và ra quyết định.
Vì vậy, AI nằm ở trung tâm của cách mạng công nghiệp lần thứ tư. Nó làm cho máy móc không chỉ thực hiện lệnh cứng, mà có thể học từ dữ liệu, nhận dạng mẫu, hỗ trợ suy luận và đưa ra quyết định trong môi trường phức tạp. Tuy nhiên, mặt trái đi cùng AI cũng lớn hơn. Mất quyền riêng tư, khủng hoảng đạo đức, phân biệt đối xử tự động, phụ thuộc công nghệ và nguy cơ mất kiểm soát là những vấn đề cần được đặt ngang hàng với năng suất và đổi mới.
Chuyển đổi số là vòng lặp cải tiến liên tục
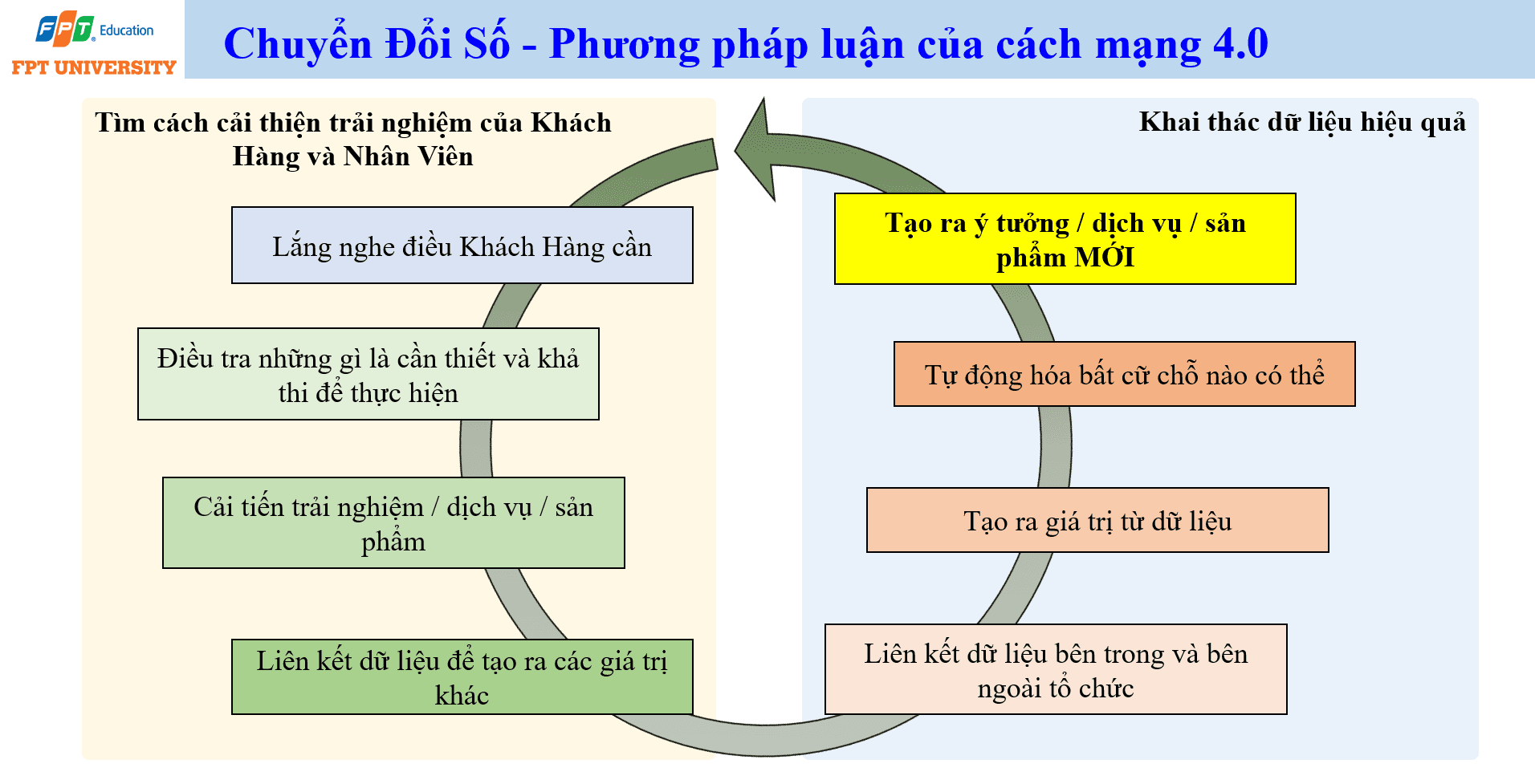
Chuyển đổi số không phải là một dự án công nghệ được thực hiện một lần rồi kết thúc. Chuyển đổi số là một vòng lặp cải tiến liên tục. Trong vòng lặp đó, tổ chức bắt đầu từ việc quan sát trải nghiệm của khách hàng và nhân viên, lắng nghe điều họ thật sự cần, điều tra những gì cần thiết và khả thi, rồi cải tiến sản phẩm, dịch vụ hoặc quy trình vận hành. Sau mỗi lần cải tiến, dữ liệu mới tiếp tục được sinh ra. Tổ chức lại phân tích dữ liệu đó để phát hiện nhu cầu mới, điểm nghẽn mới và cơ hội mới. Vì vậy, chuyển đổi số là một quá trình vận hành lâu dài, không phải một chiến dịch trang trí bằng công nghệ.
Dữ liệu giữ vai trò trung tâm trong vòng lặp này. Khi dữ liệu bên trong và bên ngoài tổ chức được liên kết, doanh nghiệp có thể tạo ra các giá trị mà trước đây chưa nhìn thấy. Dữ liệu bán hàng, marketing, kế toán, chăm sóc khách hàng, vận hành, thiết bị cảm biến, văn bản, hình ảnh và phản hồi người dùng không nên tồn tại rời rạc. Khi các nguồn dữ liệu này được kết nối đúng cách, tổ chức có thể hiểu rõ hơn hoạt động hiện tại, dự báo xu hướng, phát hiện lãng phí, tự động hóa điểm nghẽn và ra quyết định chính xác hơn.
AI trở thành một công cụ quan trọng trong chuyển đổi số vì AI giúp khai thác dữ liệu hiệu quả hơn. Nếu phần mềm truyền thống chủ yếu thực hiện các quy tắc do con người viết sẵn, AI có thể học quy luật từ dữ liệu, nhận dạng mẫu và hỗ trợ ra quyết định trong các tình huống phức tạp. Với AI, doanh nghiệp có thể tự động hóa nhiều công việc lặp lại, nâng cao chất lượng dịch vụ, cải thiện trải nghiệm người dùng và tạo ra ý tưởng mới.
Mục tiêu cuối cùng của chuyển đổi số không chỉ là đưa công nghệ vào doanh nghiệp. Mục tiêu cuối cùng là tạo ra dịch vụ mới, sản phẩm mới và phương thức vận hành mới có khả năng tạo ra nhiều giá trị hơn cho xã hội. Khi khách hàng được phục vụ tốt hơn, chi phí xã hội giảm xuống, năng suất tăng lên và sản phẩm có chất lượng cao hơn, doanh nghiệp cũng trở nên lớn mạnh hơn. Sự lớn mạnh đó không chỉ nằm ở doanh thu. Nó nằm ở năng lực thích ứng, năng lực đổi mới, năng lực khai thác dữ liệu và năng lực đóng góp vào hệ sinh thái kinh tế xã hội.
Một ví dụ kinh điển của chuyển đổi số là Grab, ban đầu Grab được sinh ra với mục đích kết nối khách hàng có như cầu đi taxi với lái xe. Tuy nhiên, trong quá trình vận hành. Dữ liệu để lại cho thấy rằng có rất nhiều khách hàng chỉ đặt xe đi từ nhà tới quán ăn, sau đó lại đặt xe quay về nhà. Điều này dẫn tới câu hỏi: Làm thế nào để tiết kiệm chi phí cho khách hàng? Câu trả lời là hãy mang đồ ăn về tận nhà cho họ. Và đó là cách mà Grab food ra đời. Thông qua đó rất nhiều thành phần trong chuỗi giá trị được hưởng lợi: không chỉ khách hàng, người lái xe có thêm việc, đầu bếp, chủ quán ăn, không chỉ những người có vị trí kinh doanh đắc địa có thể làm ăn tốt mà cả những nhà hàng ở trong ngõ cũng có thể kinh doanh dịch vụ ăn uống kiểu này. Nhưng Grab không dừng việc chuyển đổi số lại, họ vẫn tiếp tục tạo ra sản phẩm và dịch vụ mới. Điều này cho thấy chuyển đổi số chưa bao giờ là một quá trình có điểm đầu và điểm kết thúc. Nó liên tục.
Trí tuệ nhân tạo là gì?
Trí tuệ nhân tạo là một lĩnh vực và cũng là một nhóm công nghệ phần mềm nhằm giúp máy tính thực hiện một số nhiệm vụ vốn thường cần trí tuệ con người. Các nhiệm vụ đó gồm suy luận logic (logical reasoning), nhận dạng mẫu (pattern recognition), hiểu ngôn ngữ tự nhiên (natural language understanding) và đưa ra quyết định dựa trên thông tin phức tạp. Điểm cốt lõi là AI không chỉ chạy theo các quy tắc cố định. Nhiều hệ thống AI hiện đại học từ dữ liệu và điều chỉnh cách xử lý dựa trên kinh nghiệm được mã hóa trong dữ liệu.
Phần mềm thông thường được xây dựng bằng các quy tắc do lập trình viên viết trước. Nếu gặp một điều kiện, chương trình thực hiện một hành động tương ứng. Với AI, đặc biệt là các hệ thống học từ dữ liệu, quy tắc thực thi không hoàn toàn được viết trực tiếp bằng tay. Thuật toán học từ môi trường hoặc từ tập dữ liệu, sau đó tạo ra một mô hình có khả năng dự đoán, phân loại hoặc sinh kết quả. Vì vậy, cùng là phần mềm, nhưng cách hình thành hành vi của AI khác với cách hình thành hành vi của phần mềm truyền thống.
Cần phân biệt AI hẹp (narrow AI) và trí tuệ nhân tạo tổng quát (Artificial General Intelligence). Narrow AI được thiết kế để thực hiện một nhiệm vụ cụ thể. Một hệ thống theo dõi giao thông, hỗ trợ phát âm, chơi cờ, nhận dạng khuôn mặt hoặc phân loại thư rác đều có thể rất mạnh trong phạm vi của nó, nhưng không tự động chuyển sang làm tốt mọi nhiệm vụ khác. AGI là loại AI có khả năng thực hiện bất kỳ nhiệm vụ trí tuệ nào mà con người có thể làm, từ suy luận đến sáng tạo. Tuy nhiên, AGI chưa thật sự được hoàn thiện theo nghĩa một hệ thống có năng lực tổng quát, ổn định và đáng tin cậy như con người trong mọi bối cảnh.
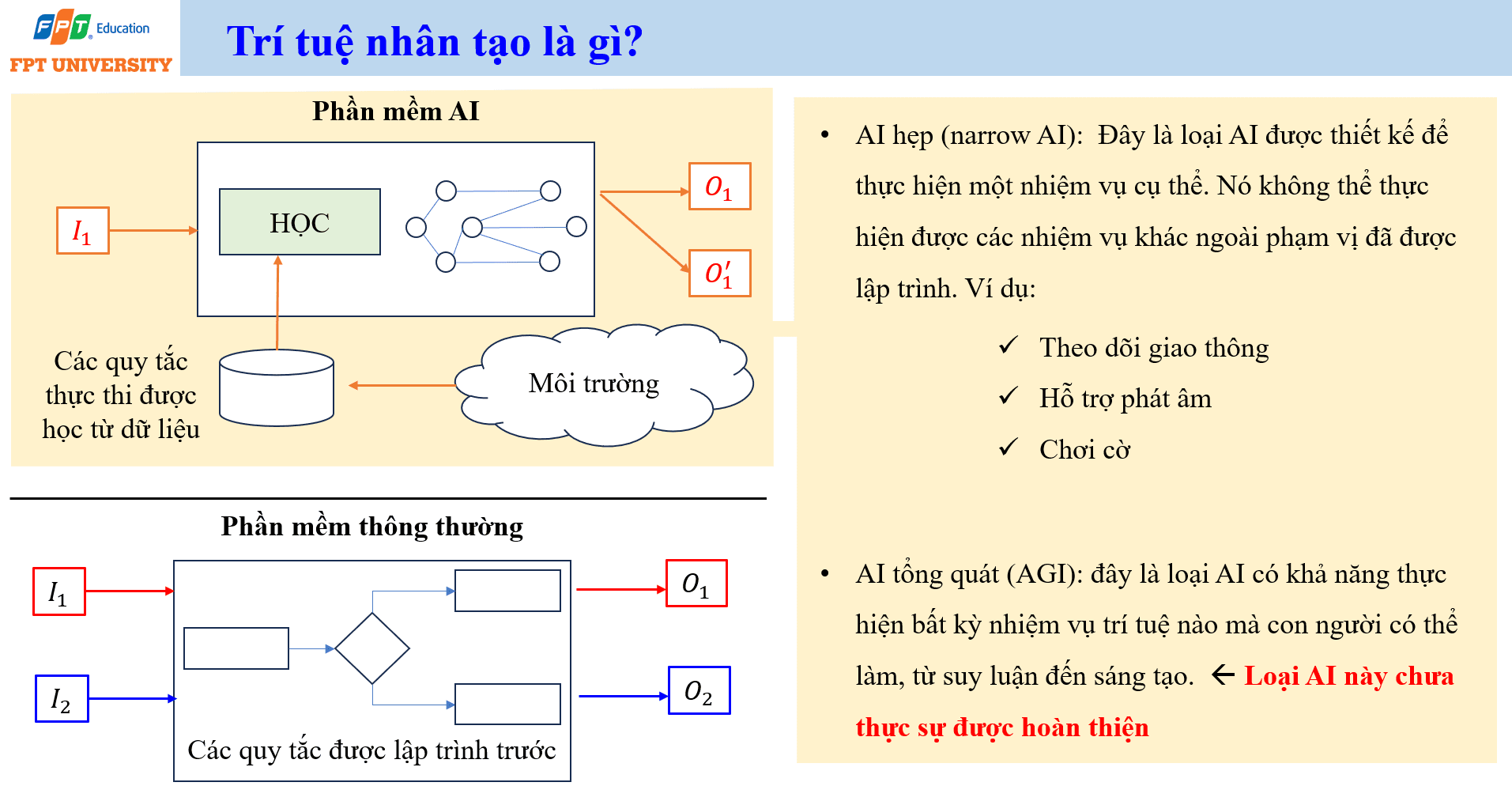
Nhận thức đúng về AI giúp tránh hai thái cực. Thái cực thứ nhất là thần thánh hóa AI, xem AI như một thực thể có thể tự hiểu mọi vấn đề. Thái cực thứ hai là xem AI chỉ như một công cụ phần mềm bình thường. Cách hiểu phù hợp hơn là AI mở rộng năng lực xử lý thông tin của con người, nhưng nó vẫn phụ thuộc vào dữ liệu, mục tiêu thiết kế, môi trường vận hành, quy trình kiểm soát và năng lực đánh giá của con người.
Tác động của AI tới lao động, sản phẩm và dịch vụ
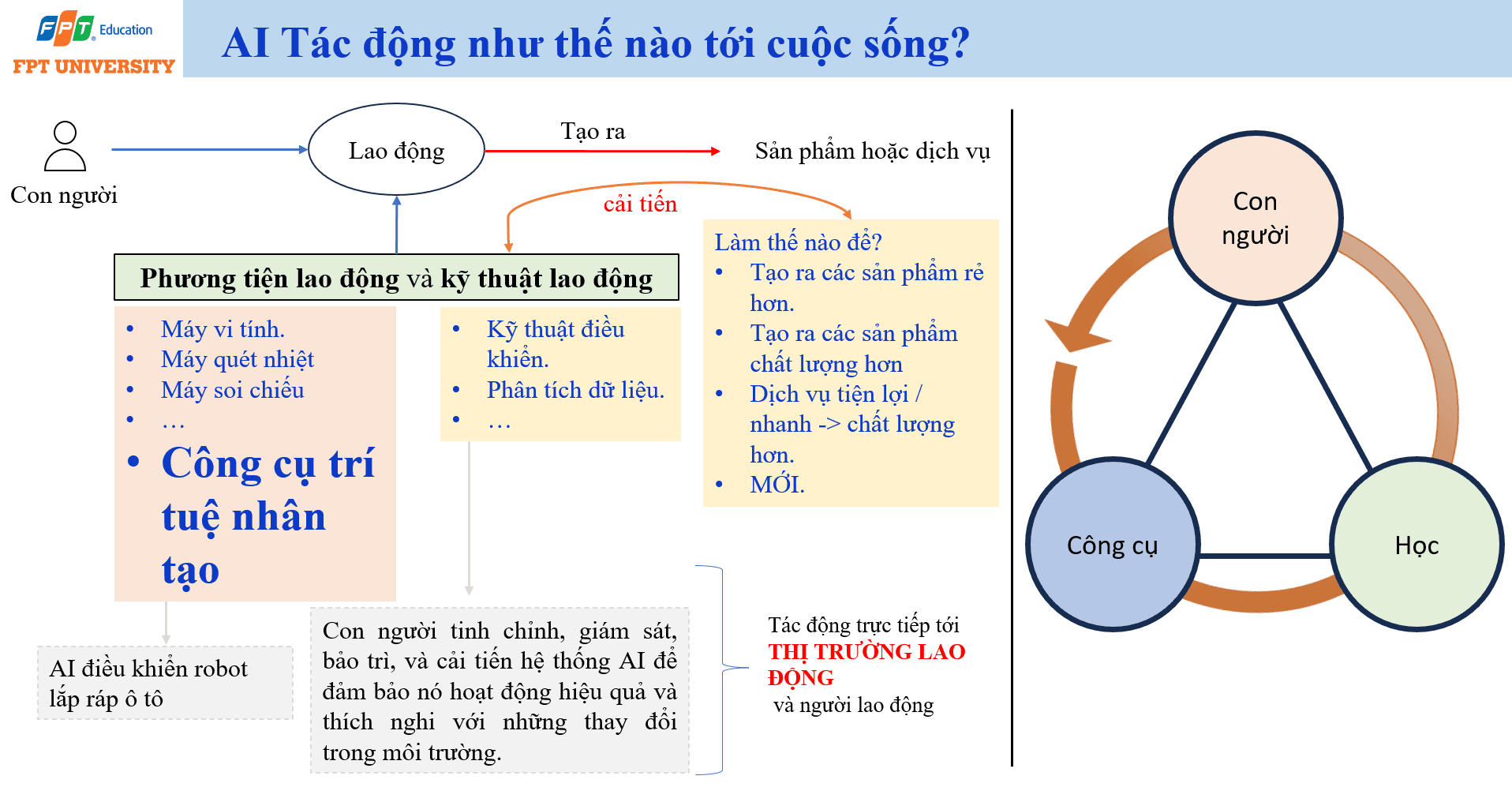
AI tác động trực tiếp đến đời sống thông qua ba hướng chính. Hướng thứ nhất là thay đổi lao động. Hướng thứ hai là cải tiến sản phẩm hoặc dịch vụ. Hướng thứ ba là tạo ra phương tiện lao động và kỹ thuật lao động mới. Ba hướng này liên kết chặt chẽ với nhau. Khi công cụ lao động thay đổi, kỹ năng lao động cũng thay đổi. Khi kỹ năng lao động thay đổi, doanh nghiệp có khả năng tạo ra sản phẩm và dịch vụ mới.
Trong sản xuất, AI có thể điều khiển robot lắp ráp ô tô, phân tích lỗi sản phẩm, dự báo bảo trì thiết bị và tối ưu quy trình vận hành. Tuy nhiên, điều này không có nghĩa con người biến mất khỏi hệ thống. Vai trò của con người chuyển dịch sang tinh chỉnh, giám sát, bảo trì và cải tiến hệ thống AI. Con người cần đảm bảo AI hoạt động hiệu quả, an toàn và thích nghi được với thay đổi trong môi trường sản xuất. Đây là sự chuyển dịch từ lao động thao tác trực tiếp sang lao động giám sát và cải tiến hệ thống.
AI cũng làm thay đổi cách tạo ra sản phẩm và dịch vụ. Công nghệ này có thể giúp tạo ra sản phẩm rẻ hơn, chất lượng hơn, dịch vụ nhanh hơn và tiện lợi hơn. Trong thương mại điện tử, AI có thể gợi ý sản phẩm phù hợp. Trong ngân hàng, AI có thể phát hiện giao dịch bất thường. Trong y tế, AI có thể hỗ trợ đọc ảnh y khoa. Trong giáo dục, AI có thể cá nhân hóa nội dung học tập. Khi được triển khai đúng, AI không chỉ giảm chi phí cho doanh nghiệp mà còn cải thiện trải nghiệm xã hội của người dùng.
Điểm cần chú ý là AI tác động trực tiếp tới thị trường lao động. Những công việc lặp lại, có dữ liệu rõ ràng và tiêu chí đánh giá cụ thể sẽ dễ bị tự động hóa hơn. Ngược lại, những công việc đòi hỏi hiểu ngữ cảnh, trách nhiệm chuyên môn, giao tiếp xã hội, đạo đức nghề nghiệp và tư duy sáng tạo sẽ không biến mất ngay, nhưng sẽ thay đổi cách thực hiện. Người lao động cần học cách dùng AI như công cụ, hiểu giới hạn của AI và phát triển năng lực mà AI khó thay thế.
AI trong hệ thống thông tin quản lý của tổ chức
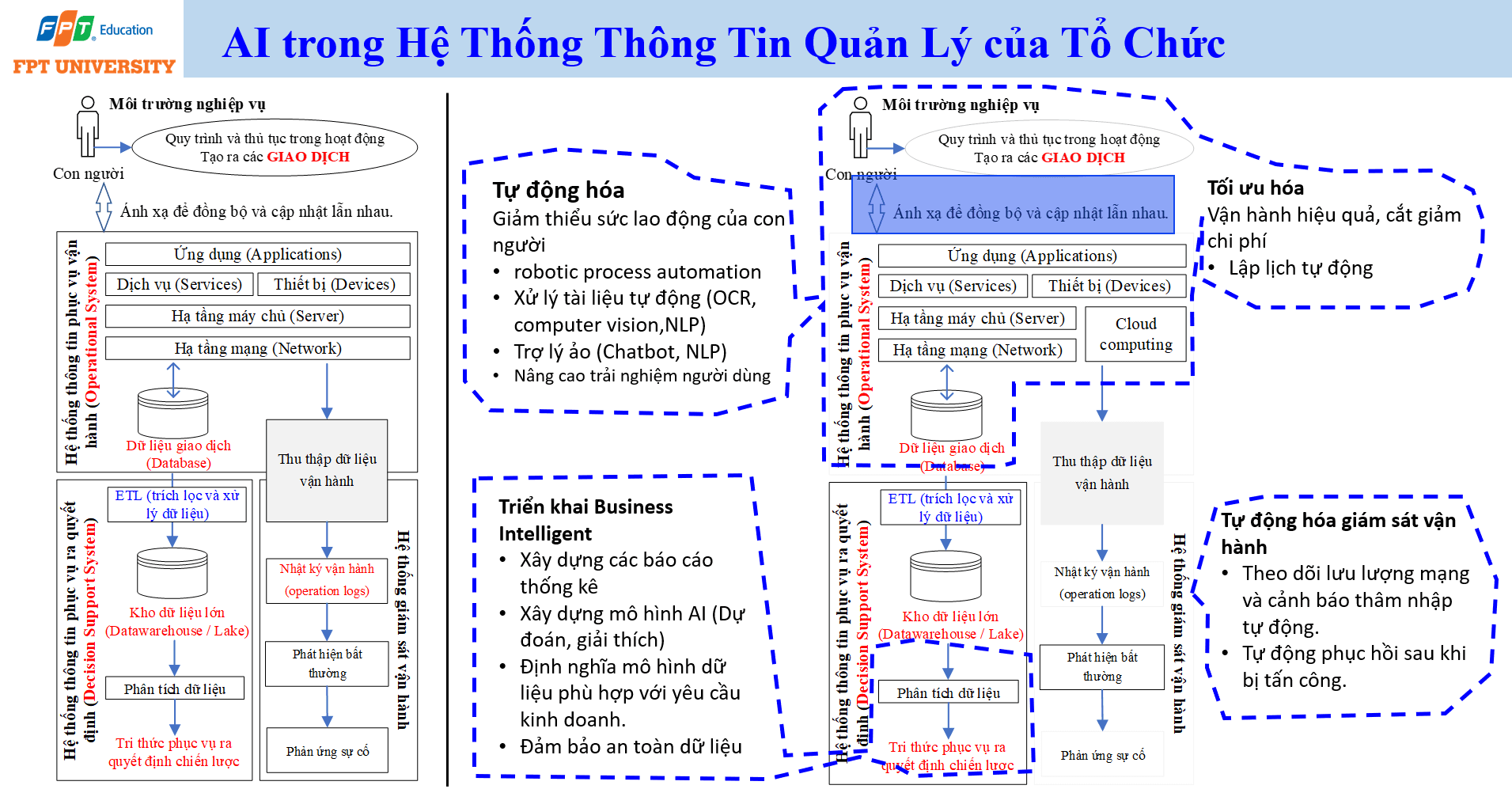
Trong tổ chức, AI thường không đứng riêng như một phần mềm độc lập. AI được tích hợp vào hệ thống thông tin quản lý (Management Information System) để hỗ trợ vận hành, tự động hóa, tối ưu hóa và ra quyết định. Khi nhìn theo cách này, AI trở thành một lớp năng lực bổ sung cho hệ thống hiện có, từ quản lý tài liệu, chăm sóc khách hàng, phân tích dữ liệu, lập lịch, giám sát an ninh đến hỗ trợ quyết định chiến lược.
- Nhóm ứng dụng đầu tiên là tự động hóa. AI có thể giảm sức lao động của con người thông qua tự động hóa quy trình bằng robot phần mềm (Robotic Process Automation), xử lý tài liệu tự động bằng nhận dạng ký tự quang học (Optical Character Recognition), thị giác máy tính (Computer Vision) và xử lý ngôn ngữ tự nhiên (Natural Language Processing). Chatbot và trợ lý ảo cũng thuộc nhóm này vì chúng giúp trả lời câu hỏi, hướng dẫn người dùng và xử lý các yêu cầu lặp lại.
- Nhóm ứng dụng thứ hai là tối ưu hóa. Tổ chức có thể dùng AI để vận hành hiệu quả hơn, cắt giảm chi phí, lập lịch tự động, xây dựng báo cáo thống kê, triển khai trí tuệ kinh doanh (Business Intelligence) và xây dựng mô hình dự đoán hoặc giải thích. Trong bối cảnh này, mô hình dữ liệu cần được định nghĩa phù hợp với yêu cầu kinh doanh. Nếu dữ liệu không phản ánh đúng nghiệp vụ, mô hình AI sẽ đưa ra kết quả thiếu giá trị, dù thuật toán có hiện đại đến đâu.
- Nhóm ứng dụng thứ ba là giám sát vận hành và an toàn. AI có thể theo dõi lưu lượng mạng, cảnh báo xâm nhập, phát hiện bất thường và hỗ trợ tự động phục hồi sau sự cố. Tuy nhiên, để làm được điều này, tổ chức cần có dữ liệu vận hành đủ tốt, quy trình phản hồi rõ ràng và đội ngũ có khả năng xác minh kết quả. AI không thay thế hoàn toàn quản trị vận hành. AI giúp mở rộng khả năng quan sát và phản ứng của tổ chức.
AI Literacy theo cấp nhân sự trong tổ chức
Muốn triển khai AI hiệu quả, tổ chức không thể chỉ đào tạo một nhóm kỹ thuật. Tổ chức cần phát triển hiểu biết về AI (AI Literacy) theo cấp nhân sự. AI Literacy là năng lực hiểu, sử dụng, đánh giá và tham gia định hình cách AI được dùng trong công việc. Mỗi nhóm nhân sự cần một mức độ AI Literacy khác nhau vì vai trò, trách nhiệm và rủi ro của họ khác nhau.
Ở cấp AI Explorer, đối tượng chính là nhân viên phổ thông. Mục tiêu đào tạo là giúp họ nhận thức cơ bản về AI và ứng dụng đơn giản. Nội dung có thể gồm khái niệm AI, ví dụ phổ biến như chatbot, dịch thuật, hỗ trợ viết nội dung và các nguyên tắc đạo đức cơ bản. Hoạt động thực hành phù hợp là dùng ChatGPT, nhận diện ứng dụng AI trong đời sống và hiểu khi nào cần kiểm tra lại kết quả AI.
Ở cấp AI Practitioner, đối tượng là nhân viên chuyên môn. Họ cần hiểu cách AI hoạt động và biết áp dụng vào công việc. Nội dung nên bao gồm Machine Learning, thiên kiến dữ liệu (data bias), quyền riêng tư, phân tích dữ liệu và hỗ trợ quy trình. Một chuyên viên marketing có thể dùng AI để phân tích phản hồi khách hàng. Một chuyên viên tài chính có thể dùng AI hỗ trợ phân tích báo cáo. Một giảng viên có thể dùng AI để tạo gợi ý phản hồi học tập. Tuy nhiên, họ vẫn phải chịu trách nhiệm đánh giá đầu ra.
Ở cấp AI Integrator, đối tượng là quản lý nhóm hoặc chuyên viên cao. Họ cần biết tích hợp AI vào quy trình làm việc và dự án. Nội dung cần nhấn mạnh triển khai công cụ AI, đánh giá hiệu quả, tích hợp vào workflow của phòng ban và thiết kế pilot nhỏ. Ở cấp AI Strategist, đối tượng là lãnh đạo cấp trung và cấp cao. Họ cần định hướng chiến lược AI cho toàn tổ chức, hiểu rủi ro đạo đức, pháp lý, an toàn thông tin và năng lực tổ chức. Đây là cấp quyết định AI có được dùng để tạo giá trị dài hạn hay chỉ tạo ra các thử nghiệm rời rạc.

Ba chiều sâu của AI Literacy (Nhận thức về AI)
AI Literacy không chỉ là biết cách nhập prompt. Nội dung bài giảng phân biệt ba chiều sâu quan trọng: hiểu biết chức năng (Functional AI Literacy), hiểu biết phản biện (Critical AI Literacy) và hiểu biết diễn ngôn (Rhetorical AI Literacy). Ba chiều sâu này giúp người dùng không dừng lại ở mức sử dụng công cụ, mà tiến tới đánh giá tác động và tham gia định hình cách xã hội dùng AI.
Functional AI Literacy là năng lực sử dụng AI như một công cụ. Người dùng biết dùng Copilot hoặc ChatGPT để viết nhanh email, sửa lỗi chính tả, gợi ý cách diễn đạt và hoàn thành công việc nhanh hơn. Mục tiêu của cấp này là tăng tốc độ, tiết kiệm công sức và nâng cao chất lượng đầu ra. Đây là cấp rất quan trọng vì phần lớn người lao động sẽ bắt đầu từ nhu cầu thực tế như viết văn bản, tóm tắt tài liệu, tạo báo cáo hoặc chuẩn bị nội dung trình bày.
Critical AI Literacy là năng lực đặt câu hỏi về cách AI hoạt động và ảnh hưởng xã hội. Người dùng không chỉ nhận kết quả từ AI mà còn kiểm tra độ tin cậy, nhận diện thiếu sót và cân nhắc trách nhiệm. Ví dụ, một email do AI viết có thể đúng ngữ pháp nhưng thiếu cảm xúc, không phù hợp quan hệ xã hội hoặc gây hiểu nhầm về ý định của người gửi. Người dùng cần tự hỏi AI có đang làm lệch văn phong không, nội dung có phù hợp bối cảnh không và ai chịu trách nhiệm nếu nội dung gây hậu quả.
Rhetorical AI Literacy là năng lực tham gia định hình cách xã hội suy nghĩ, đánh giá và sử dụng AI. Ở cấp này, người dùng có thể viết bài phân tích về việc AI có làm mất chất riêng trong giao tiếp cá nhân hay không, thiết kế công cụ AI học phong cách của từng cá nhân, hoặc tham gia thảo luận về ranh giới giữa lời nói thật và lời nói theo khuôn mẫu. Đây là cấp quan trọng đối với nhà quản lý, nhà giáo dục, nhà nghiên cứu và người thiết kế chính sách vì họ không chỉ dùng AI, mà còn ảnh hưởng đến cách cộng đồng hiểu AI.
Định hướng chính sách và môi trường phát triển AI
AI không thể phát triển bền vững nếu chỉ dựa vào doanh nghiệp riêng lẻ. Nó cần môi trường chính sách, hạ tầng dữ liệu, đầu tư nghiên cứu, nhân lực chuyên môn và cơ chế thử nghiệm phù hợp. Nội dung bài giảng nhấn mạnh các định hướng được đề cập trong Nghị quyết 57 NQ TW, trong đó có khuyến khích nghiên cứu và ứng dụng AI trong các lĩnh vực trọng yếu như y tế, giáo dục, nông nghiệp, công nghiệp và hành chính công.
Một định hướng quan trọng là xây dựng hệ sinh thái AI quốc gia. Hệ sinh thái này không chỉ gồm doanh nghiệp công nghệ. Nó cần trung tâm nghiên cứu, doanh nghiệp khởi nghiệp, quỹ đầu tư, chương trình đào tạo chuyên sâu, dữ liệu dùng chung và các cơ chế bảo vệ dữ liệu. Nếu thiếu hệ sinh thái, tổ chức triển khai AI sẽ phải phụ thuộc quá nhiều vào công nghệ bên ngoài, khó tạo năng lực nội sinh và khó giải quyết các bài toán đặc thù của quốc gia.
Chính sách AI cũng phải đặt bảo vệ dữ liệu và an ninh thông tin ở vị trí trung tâm. Hệ thống AI thường cần dữ liệu lớn, trong đó có dữ liệu cá nhân, dữ liệu vận hành, dữ liệu ngành và dữ liệu quốc gia. Nếu dữ liệu bị rò rỉ, lạm dụng hoặc dùng sai mục đích, hậu quả không chỉ là sự cố kỹ thuật mà còn là tổn hại niềm tin xã hội. Vì vậy, phát triển AI phải đi cùng quản trị dữ liệu, bảo mật hệ thống, phân quyền truy cập và trách nhiệm giải trình.
Một nội dung đáng chú ý khác là thí điểm cơ chế đặc biệt. Cơ chế này cho phép áp dụng chính sách linh hoạt hơn nhằm thúc đẩy nghiên cứu, ứng dụng và thương mại hóa công nghệ mới. Các viện nghiên cứu và trường đại học có thể tham gia thành lập doanh nghiệp từ kết quả nghiên cứu. Rủi ro trong nghiên cứu có thể được chấp nhận nếu tổ chức đã tuân thủ quy trình. Đầu tư và nhân lực quốc tế có thể được thu hút bằng cơ chế thuận lợi hơn. Nhìn rộng hơn, chính sách AI cần cân bằng giữa khuyến khích đổi mới và kiểm soát rủi ro.

Phần 2: Cơ sở về AI
Các lớp khái niệm trong AI
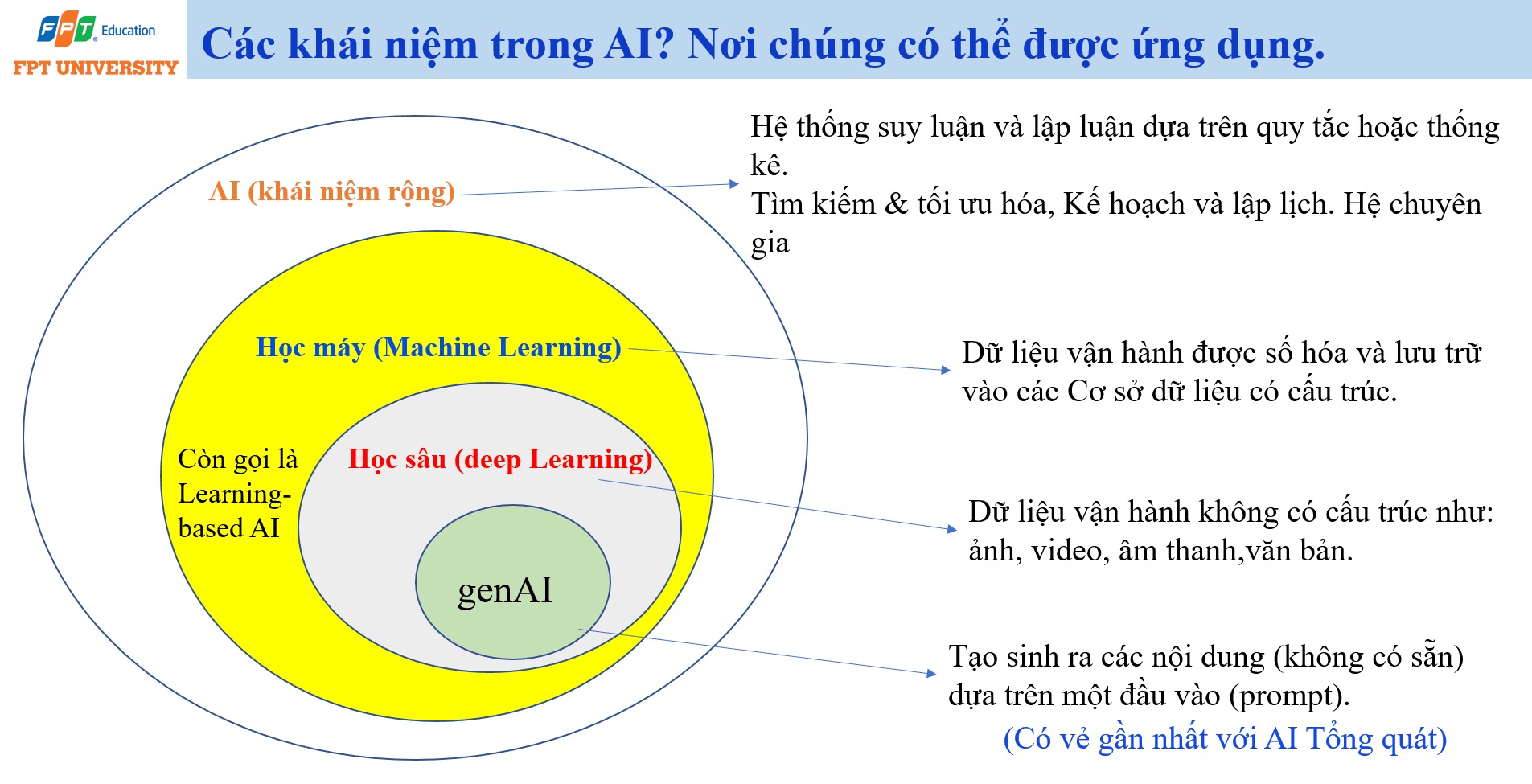
Sau khi đặt AI trong bối cảnh xã hội và tổ chức, cần hiểu cấu trúc khái niệm của AI. AI là khái niệm rộng nhất. Bên trong AI có nhiều hướng tiếp cận khác nhau, gồm các hệ thống suy luận dựa trên quy tắc, tìm kiếm và tối ưu hóa, lập kế hoạch, hệ chuyên gia, Machine Learning, Deep Learning và Generative AI. Nếu không phân biệt các lớp khái niệm này, người học dễ xem mọi công cụ thông minh là một loại giống nhau.
Machine Learning là một nhánh quan trọng của AI, thường được gọi là AI dựa trên học (learning based AI). Thay vì viết trực tiếp mọi quy tắc, con người cung cấp dữ liệu và thuật toán học ra mô hình. Machine Learning đặc biệt phù hợp với dữ liệu vận hành đã được số hóa và lưu trữ trong cơ sở dữ liệu có cấu trúc. Ví dụ, dữ liệu bán hàng, dữ liệu khách hàng, dữ liệu tài chính hoặc dữ liệu sản xuất có thể được dùng để dự báo, phân loại và tối ưu hóa.
Deep Learning là một nhánh con của Machine Learning. Điểm mạnh của Deep Learning là khả năng tự động trích xuất đặc trưng từ dữ liệu phi cấu trúc như ảnh, video, âm thanh và văn bản. Trước đây, với dữ liệu phi cấu trúc, con người phải tốn nhiều công sức để mô tả đặc trưng. Deep Learning làm giảm sự phụ thuộc này bằng cách học các biểu diễn dữ liệu qua nhiều lớp mạng neuron.
Generative AI là nhóm mô hình có khả năng tạo ra nội dung mới dựa trên đầu vào. Nội dung được tạo có thể là văn bản, hình ảnh, âm thanh, video, mã nguồn hoặc kết hợp nhiều loại dữ liệu. Large Language Model như ChatGPT, Grok hoặc Claude là trường hợp nổi bật của Generative AI trong xử lý ngôn ngữ. Generative AI có vẻ gần nhất với ý tưởng AI tổng quát trong cảm nhận của người dùng, nhưng nó vẫn không đồng nghĩa với AGI.
AI cổ điển: biểu diễn tri thức, tìm kiếm và suy luận logic
Trước khi Machine Learning trở thành hướng tiếp cận chủ đạo, AI đã có một nền tảng cổ điển rất quan trọng. AI cổ điển tập trung vào việc tạo ra hệ thống có khả năng biểu diễn tri thức, tìm kiếm lời giải và suy luận từ các quy tắc. Cách tiếp cận này không lỗi thời. Nó vẫn có giá trị trong nhiều bài toán cần tính minh bạch, cấu trúc logic rõ ràng và khả năng giải thích.
Biểu diễn tri thức (Knowledge Representation) là kỹ thuật lưu trữ và thao tác tri thức theo cấu trúc mà máy tính có thể xử lý. Các cấu trúc như frame, mạng ngữ nghĩa (semantic network) hoặc logic bậc nhất (first order logic) cho phép hệ thống mô tả sự vật, quan hệ và quy tắc. Trong hệ chuyên gia (expert system), tri thức của chuyên gia được chuyển thành tập luật. Hệ thống có thể suy luận từ các luật đó để đưa ra khuyến nghị hoặc kết luận.
Thuật toán tìm kiếm (Search Algorithm) là nhóm kỹ thuật dùng để khám phá không gian vấn đề. Trong trò chơi cờ vua, lập kế hoạch, tìm đường hoặc giải bài toán ràng buộc, hệ thống cần xem xét nhiều trạng thái và chọn đường đi phù hợp. Các thuật toán như tìm kiếm theo chiều sâu (depth first search) hoặc A star search là ví dụ điển hình. Điểm cốt lõi là bài toán được biểu diễn thành không gian trạng thái, sau đó thuật toán tìm đường đến trạng thái mục tiêu.
Suy luận logic (Logical Reasoning) dựa trên các tiền đề và quy tắc suy diễn để giải quyết vấn đề. Ngôn ngữ như Prolog từng được dùng nhiều trong lập trình logic. Cách tiếp cận này mạnh khi luật rõ ràng và tri thức có thể được biểu diễn chính xác. Tuy nhiên, nó gặp khó khăn khi thế giới quá phức tạp, dữ liệu nhiễu, quy tắc thay đổi hoặc tri thức khó mô tả đầy đủ. Chính hạn chế đó góp phần làm Machine Learning phát triển mạnh, vì Machine Learning học từ dữ liệu thay vì yêu cầu con người viết toàn bộ luật.

Machine Learning: từ dữ liệu huấn luyện đến mô hình dự đoán
Machine Learning có thể được hiểu qua hai giai đoạn chính: huấn luyện (training) và dự đoán (prediction). Trong giai đoạn training, hệ thống sử dụng dữ liệu lịch sử, thường là dữ liệu đã được gán nhãn (labeled data), để học ra một mô hình. Dữ liệu này được gọi là dữ liệu huấn luyện (training data). Nó có thể đến từ hệ thống vận hành nội bộ, sổ tay chuyên viên, hồ sơ nghiệp vụ hoặc nguồn dữ liệu mua từ bên ngoài.
Dữ liệu huấn luyện cần được biến đổi trước khi đưa vào thuật toán. Biến đổi dữ liệu (data transformation) là quá trình chuyển dữ liệu từ dạng nguyên gốc sang không gian vector dựa trên các đặc trưng quan trọng. Ví dụ, một bản ghi khách hàng có thể được chuyển thành các giá trị số đại diện cho tuổi, khu vực, hành vi mua hàng, mức chi tiêu và nhóm sản phẩm quan tâm. Nếu đặc trưng được chọn không phù hợp, mô hình sẽ học sai quan hệ giữa dữ liệu và kết quả.
Trong Machine Learning có ba nhóm thuật toán thường gặp. Học có giám sát (supervised learning) dùng dữ liệu có nhãn để học ánh xạ từ đầu vào đến đầu ra. Học không giám sát (unsupervised learning) tìm cấu trúc tự nhiên trong dữ liệu mà không cần nhãn. Học tăng cường (reinforcement learning) học thông qua tương tác với môi trường và phần thưởng. Mỗi nhóm phù hợp với một loại bài toán khác nhau.
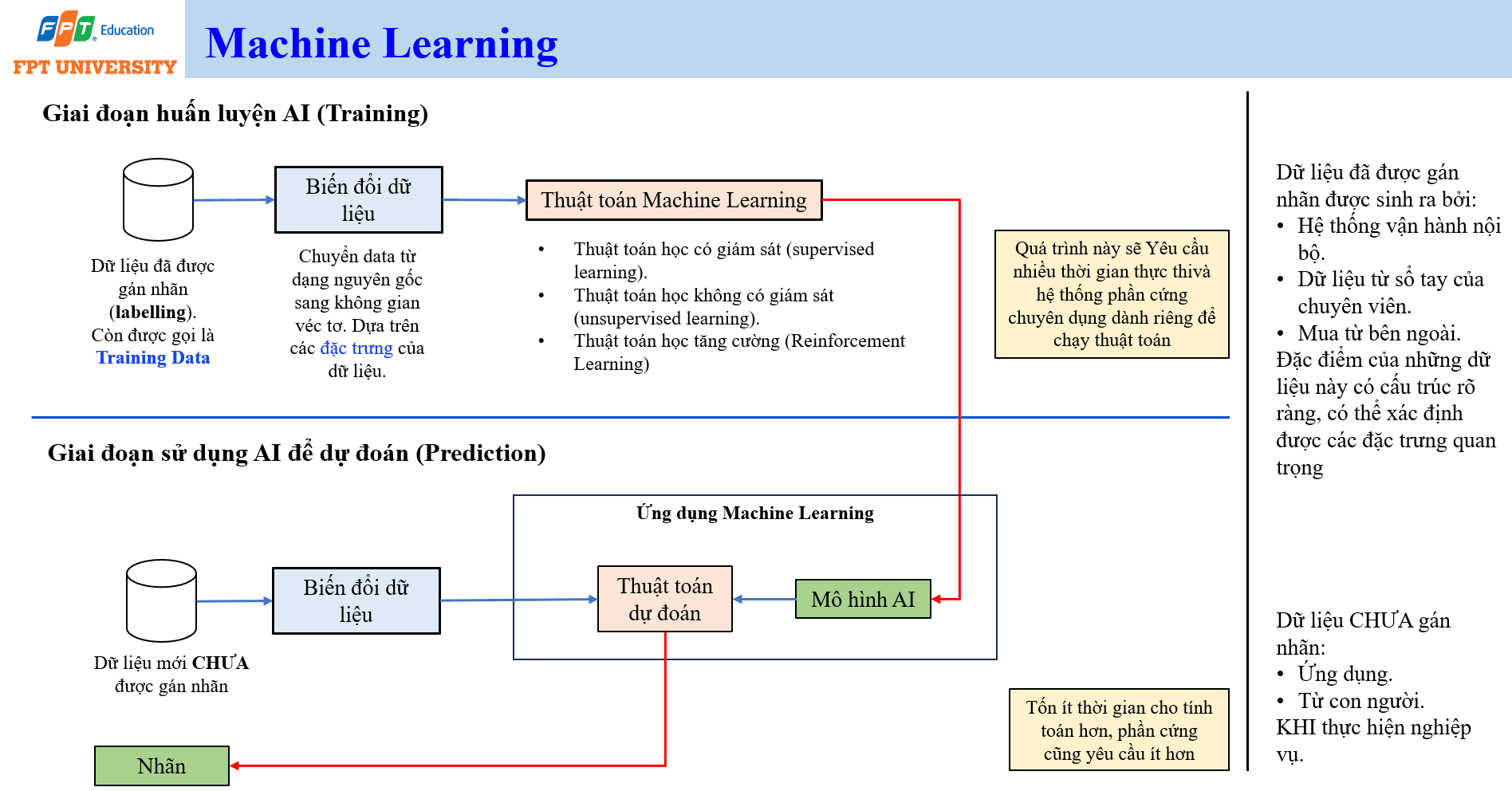
Giai đoạn training thường tốn nhiều thời gian và yêu cầu phần cứng mạnh, vì hệ thống phải tính toán trên lượng dữ liệu lớn để tìm tham số phù hợp. Sau khi training xong, mô hình được dùng trong giai đoạn prediction. Khi có dữ liệu mới chưa được gán nhãn, ứng dụng Machine Learning sẽ đưa dữ liệu vào mô hình để dự đoán nhãn, giá trị hoặc hành động phù hợp. Giai đoạn prediction thường nhẹ hơn training, nhưng vẫn cần được kiểm soát về độ trễ, chi phí và độ chính xác.
Bài toán hồi quy: mô hình AI như một hàm dự đoán
Một cách đơn giản để hiểu mô hình AI là xem nó như một hàm dự đoán. Trong bài toán hồi quy (regression), mô hình học quan hệ giữa một hoặc nhiều biến đầu vào và một giá trị đầu ra liên tục. Ví dụ trong dự đoán giá nhà, dữ liệu huấn luyện gồm diện tích nhà và giá nhà tương ứng. Thuật toán học từ dữ liệu đó để tìm ra một phương trình gần đúng, chẳng hạn giá nhà bằng 19.73 nhân với diện tích rồi cộng 527.57.
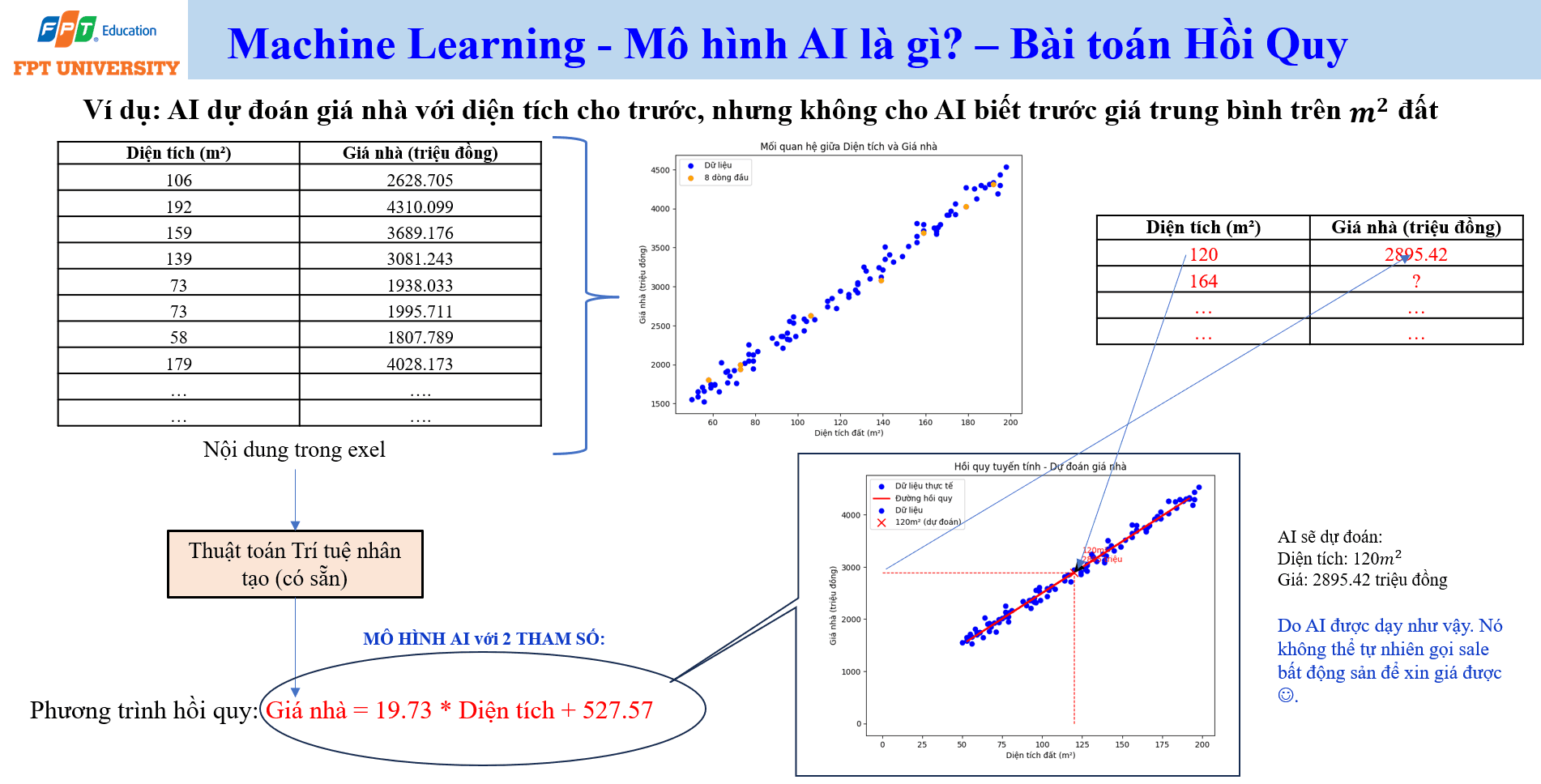
Trong ví dụ này, diện tích là đặc trưng đầu vào. Giá nhà là giá trị cần dự đoán. Hai số 19.73 và 527.57 là tham số (parameter) của mô hình hồi quy tuyến tính. Mô hình không tự nhiên hiểu thị trường bất động sản như một chuyên viên môi giới. Nó chỉ học quan hệ thống kê từ dữ liệu được cung cấp. Nếu dữ liệu huấn luyện chỉ gồm một số khu vực, mô hình sẽ phản ánh giới hạn của dữ liệu đó. Nếu dữ liệu thiếu thông tin về vị trí, chủ đầu tư, tiện ích, thời điểm giao dịch hoặc pháp lý, dự đoán có thể rất sai khi áp dụng vào thực tế.
Điều này cho thấy một nguyên tắc quan trọng: AI không tự có tri thức đầy đủ về thế giới. AI học từ dữ liệu và cấu trúc mô hình. Khi ta nói AI dự đoán giá nhà, nghĩa là mô hình dùng quan hệ đã học để tính một giá trị đầu ra cho dữ liệu mới. Nếu đưa diện tích 120 mét vuông vào mô hình, mô hình có thể dự đoán giá 2895.42 triệu đồng theo phương trình đã học. Nhưng mô hình không tự gọi điện hỏi giá thị trường, không tự kiểm tra pháp lý và không tự hiểu bối cảnh kinh tế nếu các thông tin đó không có trong dữ liệu hoặc hệ thống tích hợp.
Hồi quy là ví dụ tốt để giải thích bản chất của Machine Learning. Một mô hình AI thường không phải là một khối bí ẩn tuyệt đối. Ở mức cơ bản, nó là một hàm có tham số được học từ dữ liệu. Mức độ phức tạp của mô hình có thể tăng lên rất nhiều, nhưng nguyên tắc vẫn là dùng dữ liệu để điều chỉnh tham số nhằm giảm sai số dự đoán.
Parameter, hyperparameter và quá trình tìm nghiệm
Khi học Machine Learning, cần phân biệt tham số (parameter) và siêu tham số (hyperparameter). Parameter là giá trị được tính toán trong quá trình đào tạo với dữ liệu lịch sử. Nó là một phần của mô hình AI và được lưu lại sau khi training. Trong hồi quy tuyến tính, hệ số góc và hệ số chặn là parameter. Trong mạng neuron, trọng số và độ lệch của các kết nối là parameter.
Hyperparameter là giá trị được thiết lập trước bởi con người hoặc bởi quy trình tìm kiếm cấu hình. Nó không phải là một phần được học trực tiếp từ dữ liệu theo cùng cách với parameter. Ví dụ, số lớp của mạng neuron, tốc độ học (learning rate), số lần lặp training, kích thước batch hoặc số cụm trong một thuật toán phân cụm có thể là hyperparameter. Chọn hyperparameter không phù hợp có thể làm mô hình học chậm, học quá mức, học thiếu hoặc mắc kẹt ở kết quả kém.
Quá trình training có thể được hiểu như quá trình tìm một nghiệm tốt cho hàm mục tiêu. Mô hình cần giảm sai số giữa dự đoán và đáp án đúng. Trong không gian tham số, có thể tồn tại nghiệm toàn cục và nhiều nghiệm cục bộ. Nghiệm toàn cục là điểm tốt nhất theo hàm mục tiêu. Nghiệm cục bộ là điểm có vẻ tốt trong vùng lân cận nhưng chưa chắc là tốt nhất toàn không gian. Các thuật toán tối ưu cần di chuyển trong không gian tham số để tìm nghiệm đủ tốt.
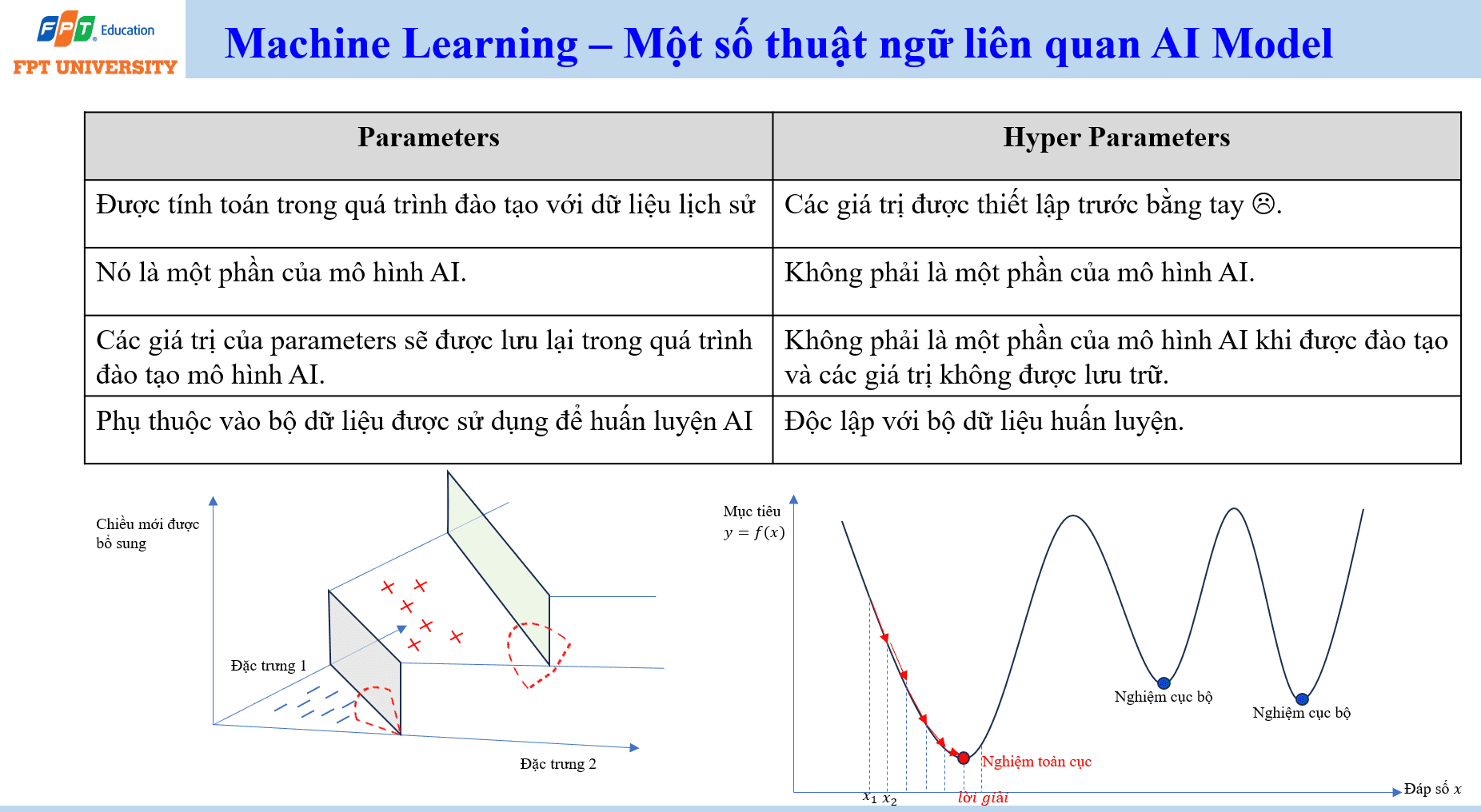
Điều này giải thích vì sao training có thể khó. Khi số đặc trưng tăng, số parameter tăng và không gian tìm kiếm trở nên rất lớn. Nếu dữ liệu phức tạp, mô hình có thể gặp nhiều vùng nghiệm khác nhau. Nếu dữ liệu nhiễu hoặc thiếu đại diện, mô hình có thể học các quan hệ sai. Vì vậy, Machine Learning không chỉ là chọn thuật toán. Nó đòi hỏi hiểu dữ liệu, chọn đặc trưng, thiết kế mô hình, điều chỉnh hyperparameter, đánh giá kết quả và kiểm soát rủi ro khi đưa vào vận hành.
Phân loại dữ liệu và phân cụm dữ liệu
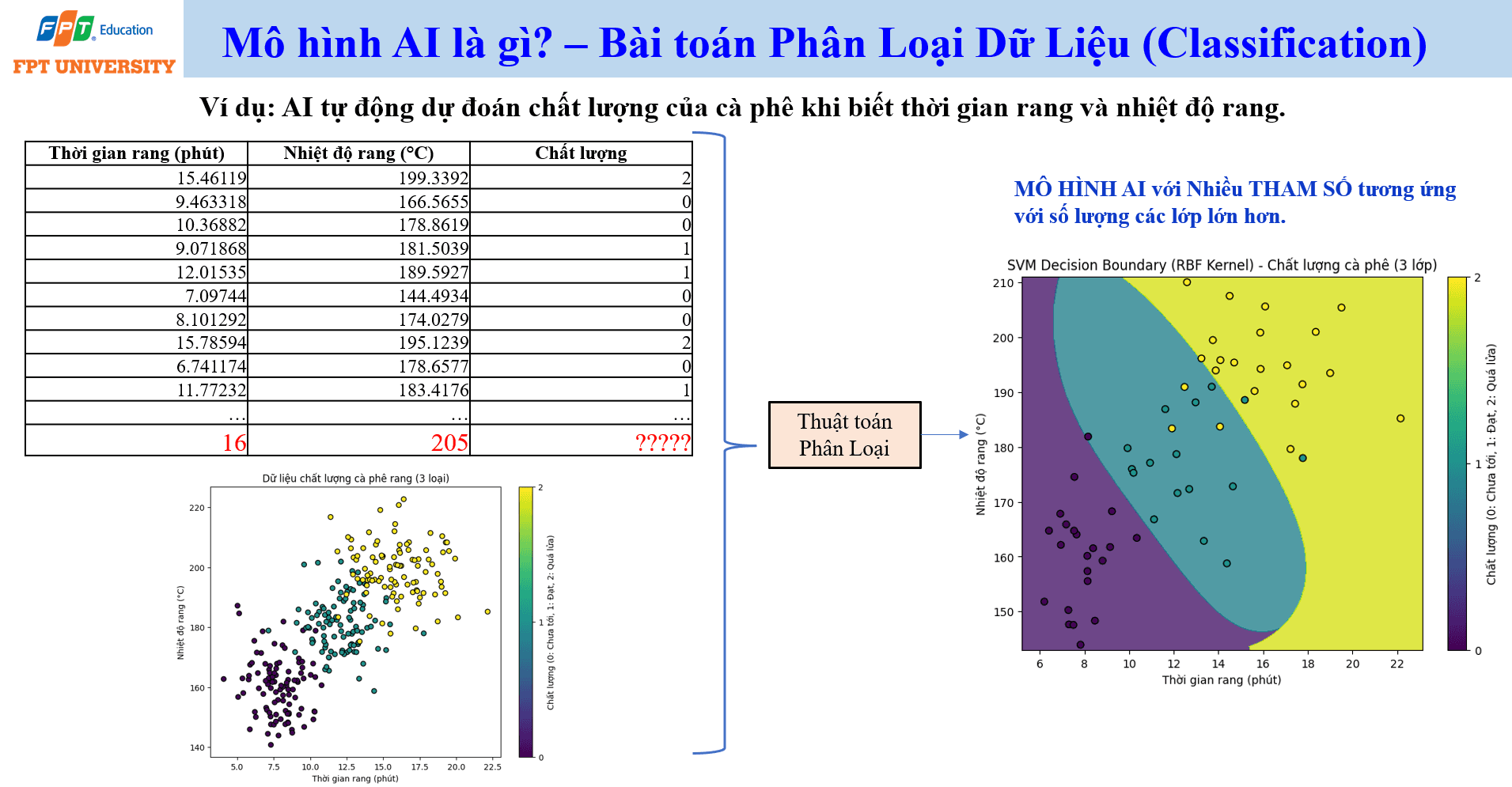
Bên cạnh hồi quy, phân loại dữ liệu (classification) là một bài toán rất phổ biến. Trong classification, mô hình học cách gán một đối tượng vào một trong các lớp đã biết. Ví dụ, chất lượng cà phê có thể được dự đoán dựa trên thời gian rang và nhiệt độ rang. Dữ liệu huấn luyện gồm nhiều dòng, mỗi dòng có thời gian rang, nhiệt độ rang và nhãn chất lượng. Khi có một mẫu mới với thời gian rang 16 phút và nhiệt độ 205 độ C, mô hình sẽ dự đoán mẫu đó thuộc lớp chất lượng nào.
Classification phù hợp với nhiều bài toán thực tế. Trong ngân hàng, mô hình có thể phân loại giao dịch là bình thường hoặc bất thường. Trong y tế, mô hình có thể hỗ trợ phân loại ảnh y khoa theo nguy cơ bệnh. Trong giáo dục, mô hình có thể dự đoán nhóm sinh viên có nguy cơ trượt môn. Trong an toàn thông tin, mô hình có thể phân loại email là thư thường hoặc phishing. Điểm chung là hệ thống cần dữ liệu có nhãn để học ranh giới giữa các lớp.
Phân cụm dữ liệu (clustering) thuộc nhóm học không giám sát. Ở đây, mô hình không được dạy trước nhãn đúng. Thuật toán tự tìm các nhóm tự nhiên dựa trên đặc tính của dữ liệu. Ví dụ, dữ liệu khách hàng có thể được phân thành các nhóm hành vi mua sắm khác nhau mà trước đó doanh nghiệp chưa đặt tên. Sau khi phân cụm, con người cần phân tích ý nghĩa của từng cụm để đặt tên và quyết định hành động phù hợp.
Sự khác nhau giữa classification và clustering rất quan trọng. Classification trả lời câu hỏi đối tượng này thuộc lớp nào trong các lớp đã biết. Clustering trả lời câu hỏi dữ liệu có thể được chia thành những nhóm tự nhiên nào. Classification cần nhãn. Clustering không cần nhãn nhưng cần con người giải thích ý nghĩa cụm. Trong cả hai trường hợp, chất lượng dữ liệu và đặc trưng đầu vào quyết định rất lớn đến giá trị của mô hình.
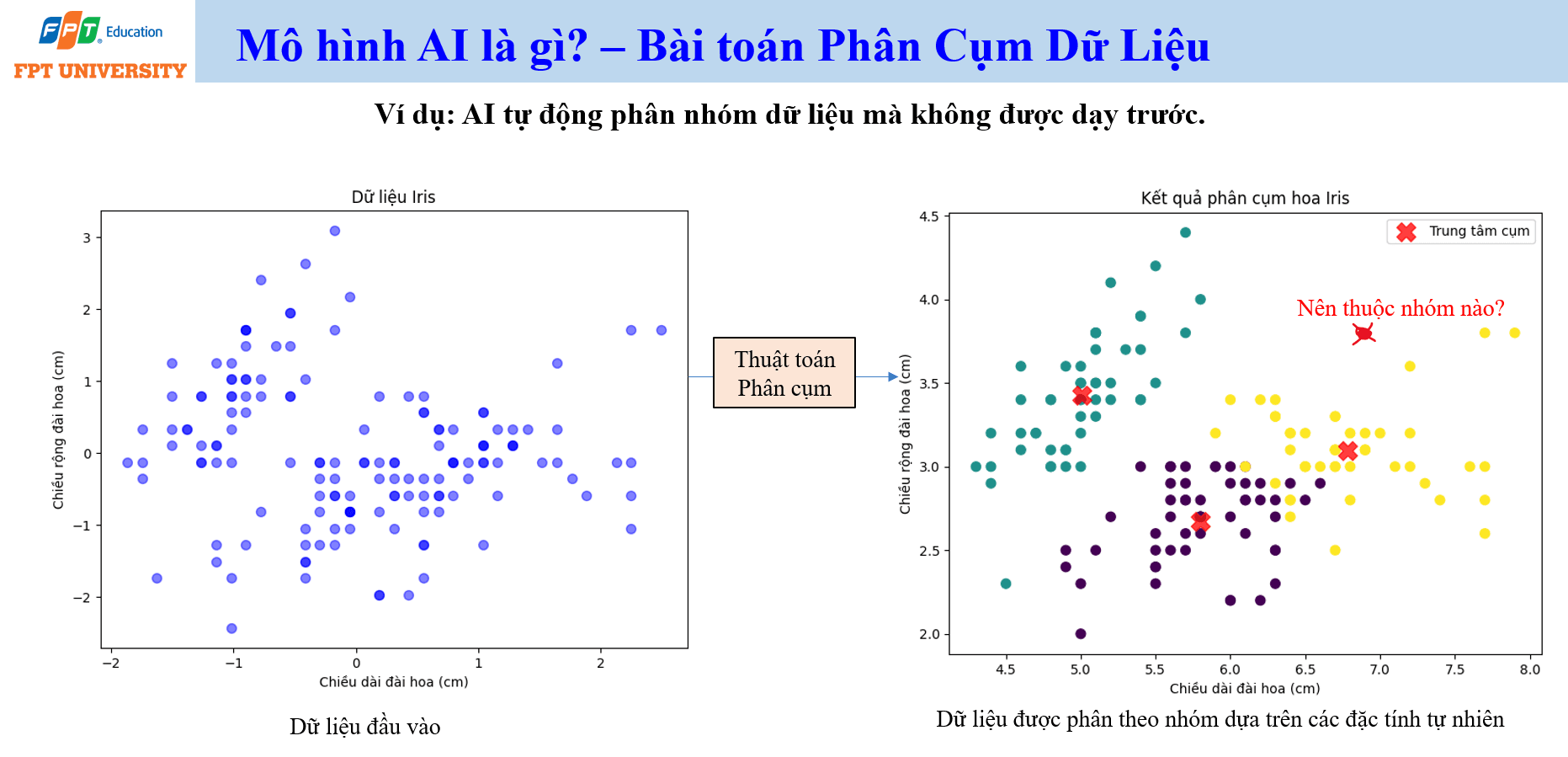
Điểm mạnh và điểm yếu của Machine Learning truyền thống
Machine Learning truyền thống rất hiệu quả khi làm việc với dữ liệu có cấu trúc. Dữ liệu có cấu trúc thường nằm trong bảng, có cột rõ ràng và ý nghĩa nghiệp vụ xác định. Ví dụ, bài toán giá bất động sản có thể có các cột như diện tích, vị trí, chủ đầu tư và đơn giá. Chuyên gia nghiệp vụ có thể xác định các đặc trưng quan trọng, mã hóa dữ liệu dạng phân loại, chuẩn hóa giá trị số và kết hợp nhiều biến để tạo đầu vào cho mô hình.
Nhiều kỹ thuật xử lý dữ liệu có cấu trúc tuy đơn giản nhưng hiệu quả. Mã hóa one hot có thể chuyển biến phân loại thành vector số. Chuẩn hóa min max có thể đưa các giá trị về cùng thang đo. Đánh trọng số có thể phản ánh tầm quan trọng khác nhau của từng đặc trưng. Khi dữ liệu có cấu trúc tốt, Machine Learning có thể tạo ra mô hình dự báo, phân loại và tối ưu hóa có giá trị cao trong vận hành.
Vấn đề xuất hiện khi dữ liệu là phi cấu trúc. Hình ảnh, video, âm thanh, văn bản và luồng cảm biến không có sẵn các cột đặc trưng đơn giản như dữ liệu bảng. Nếu muốn máy tính nhận ra một người tên Linh trong ảnh, ta phải trả lời câu hỏi đặc trưng nào giúp nhận diện Linh. Với con người, việc nhận ra khuôn mặt có vẻ tự nhiên. Nhưng với máy tính, ảnh chỉ là ma trận điểm ảnh. Với bài thơ, câu hỏi lại là đặc trưng nào thể hiện nội dung, cảm xúc, nhịp điệu và phong cách. Với dữ liệu luồng, đặc trưng có thể nằm trong biến động theo thời gian.
Điểm yếu của Machine Learning truyền thống là phụ thuộc nhiều vào đặc trưng do con người thiết kế. Khi đặc trưng khó mô tả hoặc dữ liệu quá phức tạp, việc xử lý thủ công trở nên tốn kém và dễ mất thông tin. Đây là lý do Deep Learning trở nên quan trọng. Deep Learning giúp mô hình tự học biểu diễn dữ liệu qua nhiều lớp, từ đó xử lý tốt hơn dữ liệu phi cấu trúc.
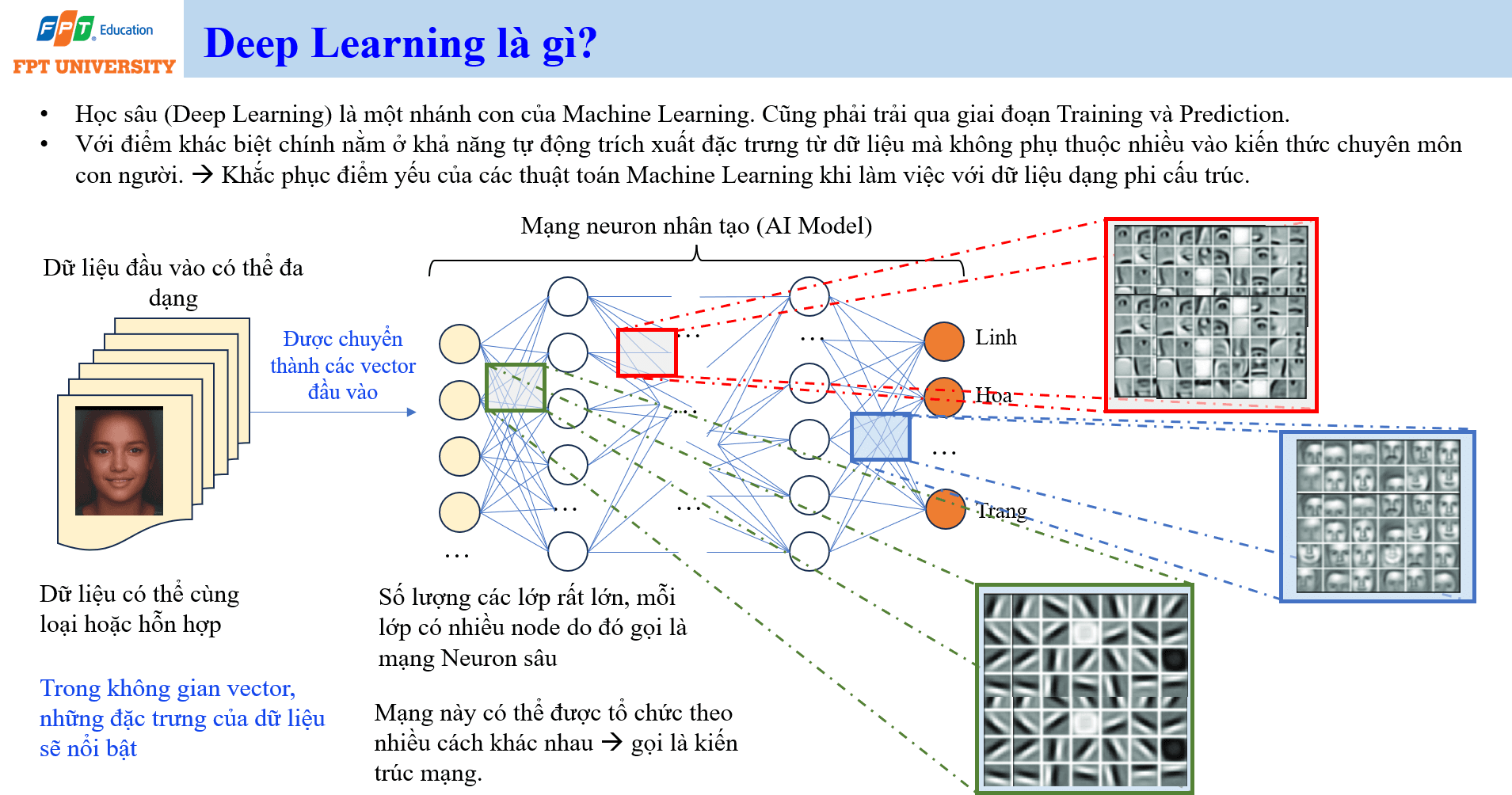
Deep Learning và khả năng tự trích xuất đặc trưng
Học sâu (Deep Learning) là một nhánh con của Machine Learning. Deep Learning vẫn phải trải qua training và prediction, nhưng điểm khác biệt chính nằm ở khả năng tự động trích xuất đặc trưng từ dữ liệu. Thay vì phụ thuộc hoàn toàn vào chuyên gia để thiết kế đặc trưng, mạng neuron sâu có thể học các biểu diễn trung gian qua nhiều lớp. Các lớp đầu có thể học đặc trưng đơn giản, các lớp sau kết hợp chúng thành đặc trưng phức tạp hơn.
Mạng neuron nhân tạo (Artificial Neural Network) gồm nhiều lớp, mỗi lớp có nhiều nút tính toán. Khi số lượng lớp lớn, ta gọi đó là mạng neuron sâu. Dữ liệu đầu vào có thể là ảnh, văn bản, âm thanh hoặc dữ liệu hỗn hợp. Dữ liệu này được chuyển thành vector đầu vào. Trong không gian vector, các đặc trưng của dữ liệu có thể trở nên rõ hơn để mô hình phân biệt, so sánh hoặc dự đoán.
Ví dụ, để nhận diện người trong ảnh, Deep Learning không cần con người mô tả thủ công toàn bộ đặc trưng của mắt, mũi, miệng, góc mặt hoặc ánh sáng. Mô hình có thể học từ rất nhiều ảnh để tự xây dựng biểu diễn phù hợp. Với văn bản, mô hình có thể học quan hệ giữa từ, cụm từ, ngữ cảnh và ý nghĩa. Với âm thanh, mô hình có thể học đặc trưng tần số, nhịp và mẫu phát âm.
Deep Learning có thể được tổ chức theo nhiều kiến trúc mạng khác nhau. Kiến trúc mạng quyết định cách dữ liệu đi qua mô hình, cách các lớp kết nối với nhau và loại quan hệ nào được học tốt hơn. Vì vậy, khi nói Deep Learning, ta không nói về một thuật toán duy nhất. Ta nói về một họ phương pháp sử dụng nhiều lớp tính toán để học biểu diễn dữ liệu phức tạp. Điểm mạnh này làm Deep Learning trở thành nền tảng của thị giác máy tính, xử lý ngôn ngữ tự nhiên, mô hình tạo sinh và nhiều hệ thống AI hiện đại.
Các kỹ thuật Deep Learning và ứng dụng
Deep Learning có nhiều nhóm ứng dụng lớn. Thị giác máy tính (Computer Vision) tập trung vào xử lý hình ảnh và video. Các nhiệm vụ phổ biến gồm phân loại ảnh, phát hiện đối tượng, phân đoạn ảnh, nhận diện khuôn mặt, theo dõi đối tượng và nhận diện hành động. Những nhiệm vụ này có giá trị trong sản xuất, an ninh, giao thông, y tế, bán lẻ và nhiều lĩnh vực khác. Thách thức của Computer Vision gồm dữ liệu hạn chế, điều kiện ánh sáng thay đổi, nhiễu môi trường và yêu cầu xử lý thời gian thực.
Xử lý ngôn ngữ tự nhiên (Natural Language Processing) tập trung vào dữ liệu văn bản và ngôn ngữ. Các nhiệm vụ gồm phân tích cảm xúc, nhận diện thực thể tên (Named Entity Recognition), tóm tắt văn bản, dịch máy, hỏi đáp tự động, trích xuất thông tin và sinh ngôn ngữ. NLP khó vì ngôn ngữ phụ thuộc mạnh vào ngữ cảnh, văn hóa, miền tri thức và cách diễn đạt. Một câu có thể mang nhiều nghĩa khác nhau tùy bối cảnh. Vì vậy, mô hình NLP cần học không chỉ từ từ đơn lẻ mà còn từ quan hệ ngữ nghĩa và cấu trúc văn bản.
Học sâu tăng cường (Deep Reinforcement Learning) kết hợp Deep Learning với reinforcement learning. Hướng này phù hợp với các nhiệm vụ cần học chính sách hành động, như chơi game, điều khiển robot, tối ưu hóa chiến lược hoặc ra quyết định trong môi trường động. Ưu điểm là hệ thống có thể học chính sách tối ưu thông qua tương tác. Thách thức là hiệu quả dữ liệu, độ an toàn khi thử nghiệm và khả năng triển khai trong môi trường thực.
Mô hình tạo sinh (Generative Model) là nhóm mô hình dự đoán hoặc tạo ra dữ liệu mới. Dữ liệu này có thể là văn bản, hình ảnh, âm thanh, video hoặc kết hợp nhiều loại. Generative Model là nền tảng của nhiều công cụ AI hiện đại vì nó không chỉ phân tích dữ liệu có sẵn, mà còn tạo ra nội dung mới theo yêu cầu. Tuy nhiên, khả năng tạo sinh cũng đi kèm rủi ro như tạo thông tin sai, tạo nội dung giả, vi phạm bản quyền hoặc làm mờ ranh giới giữa nội dung thật và nội dung do máy sinh.

Computer Vision và NLP trong thực tế
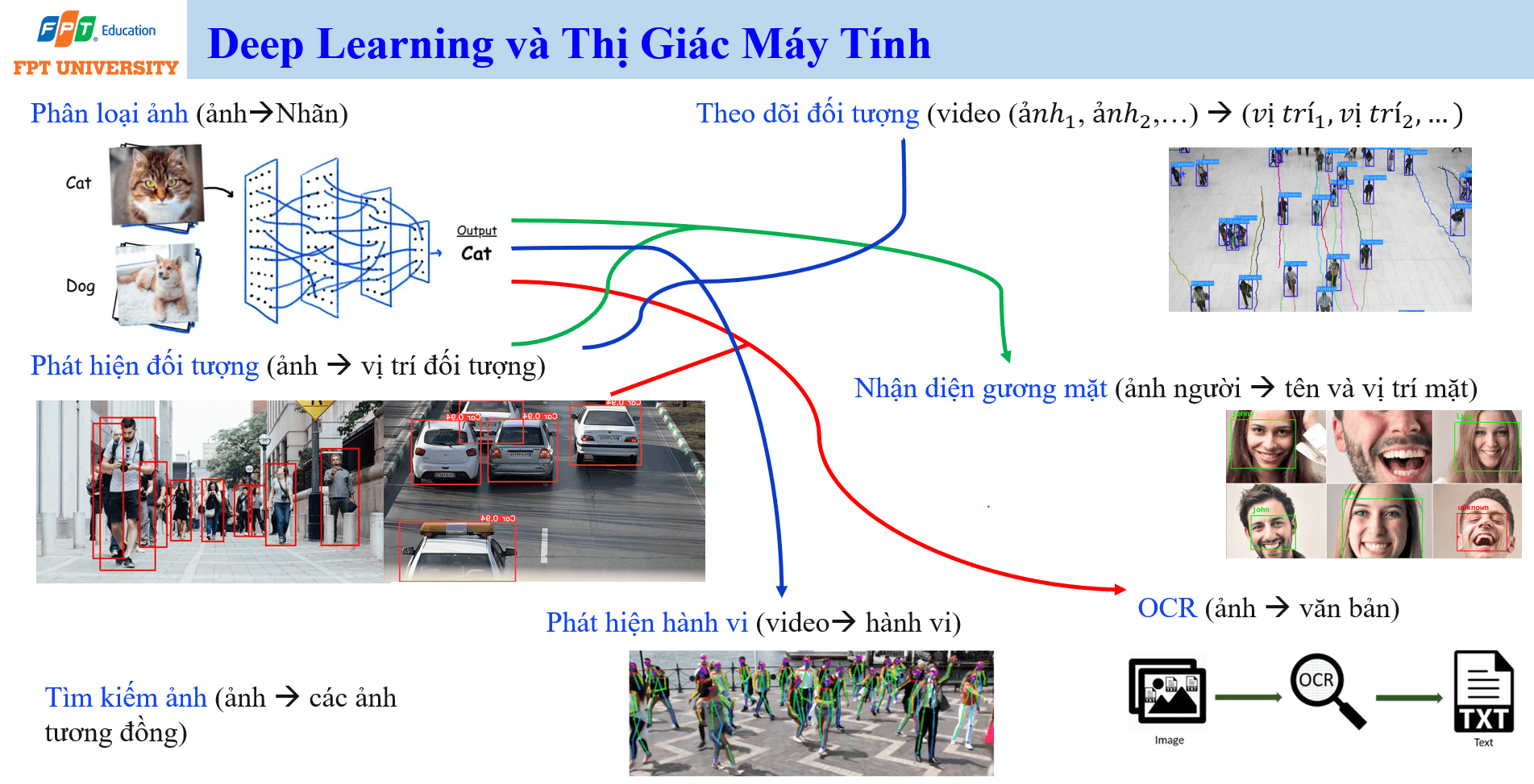
Computer Vision giúp máy tính hiểu dữ liệu hình ảnh và video. Một nhiệm vụ cơ bản là phân loại ảnh, trong đó đầu vào là ảnh và đầu ra là nhãn. Ví dụ, mô hình có thể phân loại ảnh chứa mèo, chó, xe ô tô hoặc sản phẩm lỗi. Nhiệm vụ phức tạp hơn là phát hiện đối tượng, trong đó mô hình không chỉ nói ảnh có gì mà còn xác định vị trí đối tượng trong ảnh. Theo dõi đối tượng trong video lại cần duy trì nhận dạng đối tượng qua nhiều khung hình liên tiếp.
Computer Vision còn có nhiều ứng dụng quan trọng khác. Nhận diện khuôn mặt biến ảnh người thành tên và vị trí khuôn mặt. Nhận dạng ký tự quang học chuyển ảnh tài liệu thành văn bản. Phát hiện hành vi trong video có thể hỗ trợ an ninh, giao thông hoặc phân tích vận hành. Tìm kiếm ảnh cho phép dùng một ảnh để tìm các ảnh tương đồng. Các ứng dụng này cho thấy AI không chỉ xử lý số liệu bảng, mà có thể xử lý trực tiếp dữ liệu thị giác vốn rất gần với cách con người quan sát thế giới.
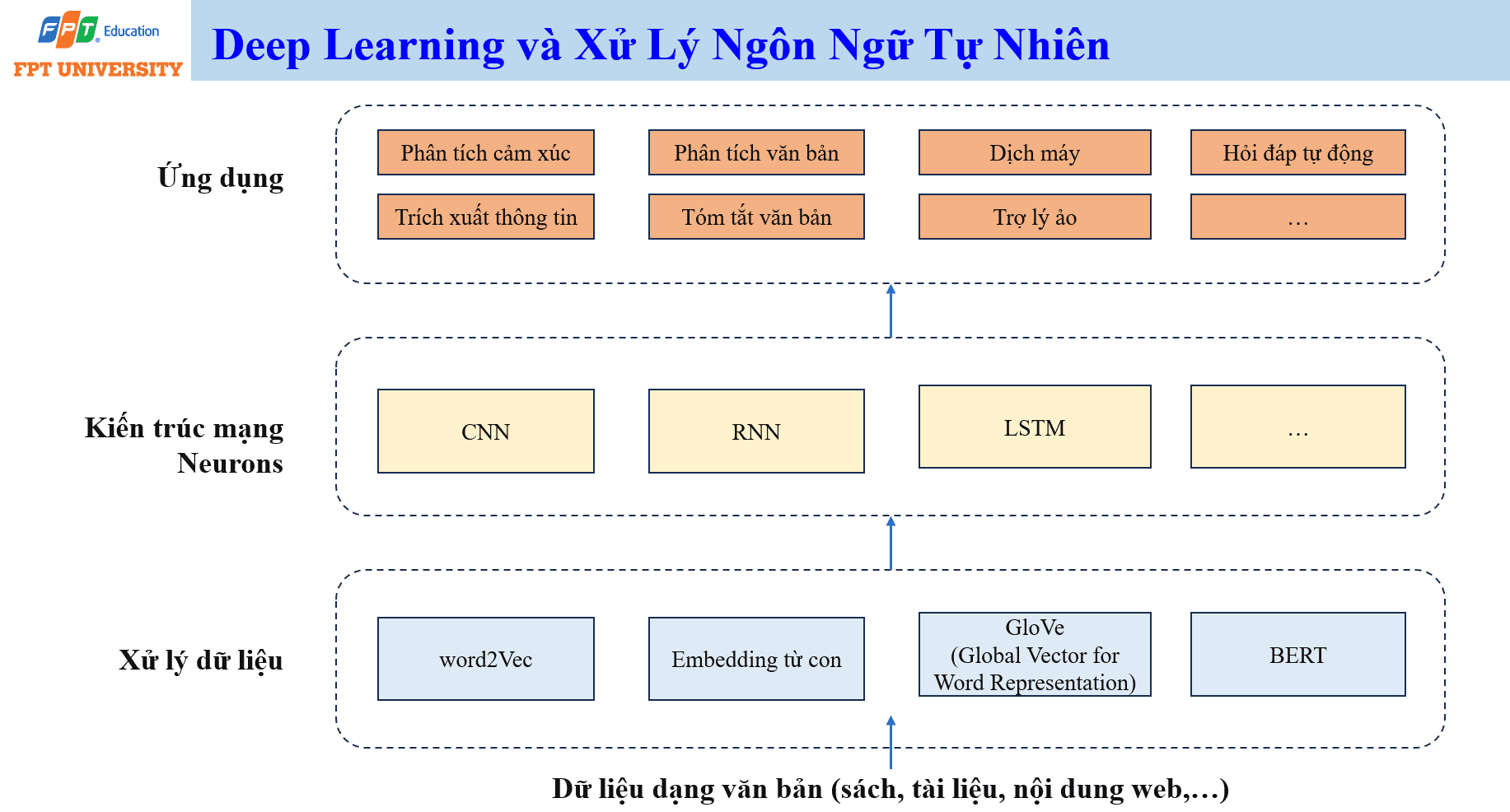
NLP xử lý dữ liệu văn bản từ sách, tài liệu, nội dung web, email, báo cáo và hội thoại. Trước khi mô hình có thể xử lý văn bản, từ và câu cần được biến đổi thành biểu diễn số. Các kỹ thuật như Word2Vec, embedding từ con và GloVe giúp chuyển từ thành vector. Các kiến trúc như CNN, RNN, LSTM và BERT hỗ trợ mô hình học đặc trưng ngôn ngữ ở các mức khác nhau. BERT đặc biệt quan trọng vì nó học ngữ cảnh hai chiều và tạo nền tảng cho nhiều nhiệm vụ hiểu văn bản.
Ứng dụng NLP rất rộng, gồm phân tích cảm xúc, phân tích văn bản, dịch máy, hỏi đáp tự động, trích xuất thông tin, tóm tắt văn bản và trợ lý ảo. Khi được tích hợp vào hệ thống tổ chức, NLP có thể giúp xử lý hồ sơ, phân loại yêu cầu khách hàng, tổng hợp báo cáo, tìm kiếm tri thức nội bộ và hỗ trợ ra quyết định. Tuy nhiên, NLP cũng cần kiểm soát rủi ro về sai ngữ cảnh, thiên kiến ngôn ngữ, dữ liệu nhạy cảm và trách nhiệm khi nội dung sinh ra được dùng trong công việc.
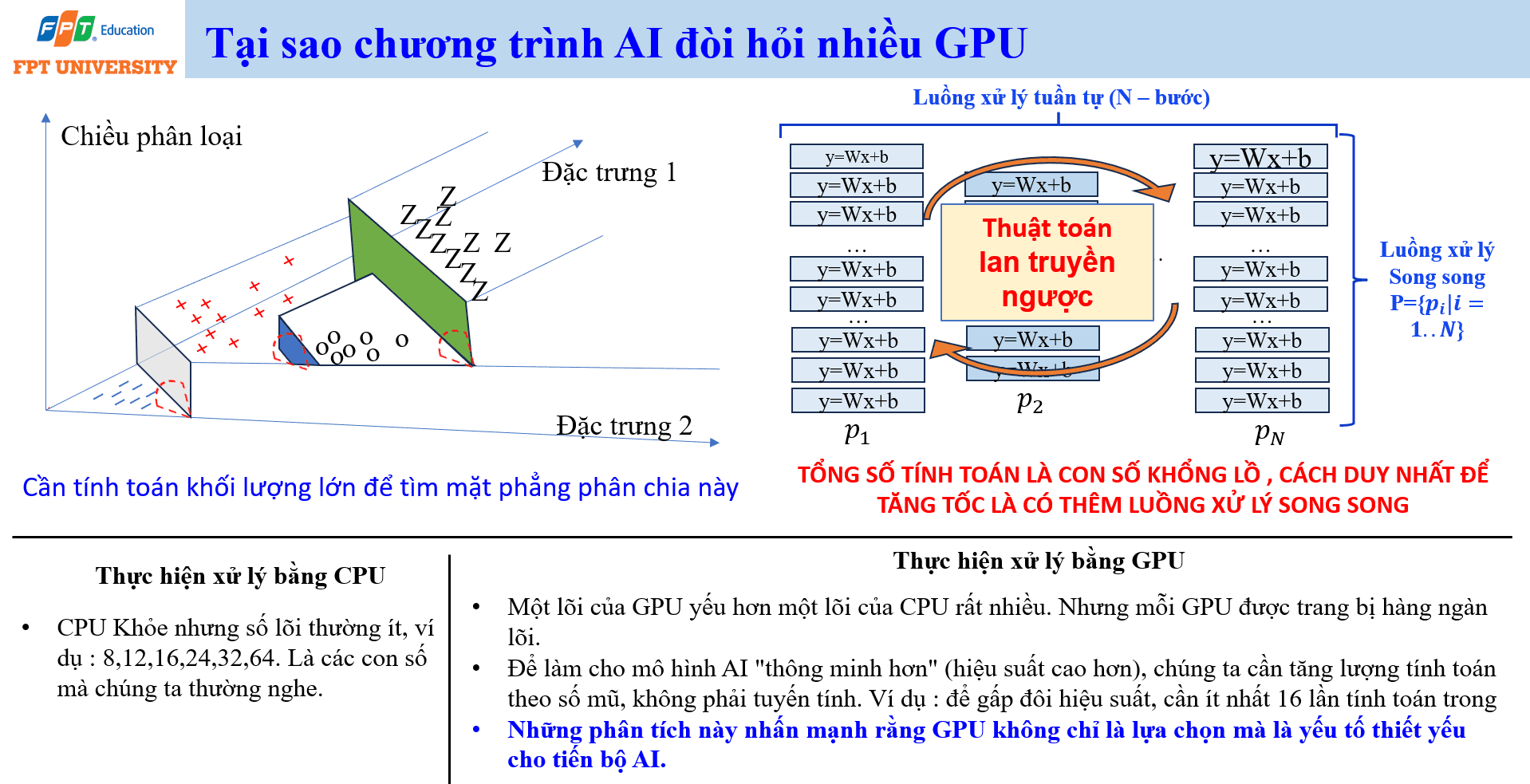
Vì sao AI cần nhiều GPU ?
Một câu hỏi thường gặp là vì sao chương trình AI hiện đại cần nhiều bộ xử lý đồ họa (Graphics Processing Unit). Câu trả lời nằm ở khối lượng tính toán rất lớn và khả năng xử lý song song. Trong mạng neuron, rất nhiều phép tính có dạng y bằng W nhân x cộng b. Mỗi lớp của mạng thực hiện hàng loạt phép nhân ma trận, cộng vector và biến đổi phi tuyến. Khi số lớp, số nút và kích thước dữ liệu tăng, số phép tính tăng lên rất nhanh.
Bộ xử lý trung tâm (Central Processing Unit) có lõi mạnh, linh hoạt và phù hợp với nhiều tác vụ tuần tự. Tuy nhiên, số lõi CPU thường không quá lớn, ví dụ 8, 12, 16, 24, 32 hoặc 64 lõi. GPU có từng lõi yếu hơn lõi CPU, nhưng có hàng nghìn lõi và được thiết kế để xử lý song song. Với bài toán AI, đặc biệt là nhân ma trận và xử lý tensor, khả năng song song của GPU giúp tăng tốc đáng kể.
Trong training, mô hình cần lan truyền tiến (forward propagation) để tính đầu ra, sau đó dùng lan truyền ngược (backpropagation) để tính gradient và cập nhật parameter. Quá trình này lặp lại rất nhiều lần trên dữ liệu lớn. Nếu xử lý tuần tự bằng CPU, thời gian có thể quá dài. GPU chia nhỏ phép tính thành nhiều luồng song song, giúp rút ngắn thời gian training. Đây là lý do GPU trở thành hạ tầng thiết yếu cho Deep Learning.
Khi muốn mô hình AI thông minh hơn theo nghĩa hiệu suất cao hơn trên nhiệm vụ phức tạp hơn, ta thường phải tăng dữ liệu, tăng số parameter, tăng kích thước mô hình hoặc tăng số bước training. Lượng tính toán vì vậy có thể tăng rất mạnh, không chỉ tăng tuyến tính. Điều này giải thích vì sao tiến bộ AI hiện đại gắn chặt với năng lực phần cứng, trung tâm dữ liệu, GPU, tối ưu hóa thuật toán và chi phí năng lượng. AI không chỉ là phần mềm. AI còn là bài toán hạ tầng tính toán.
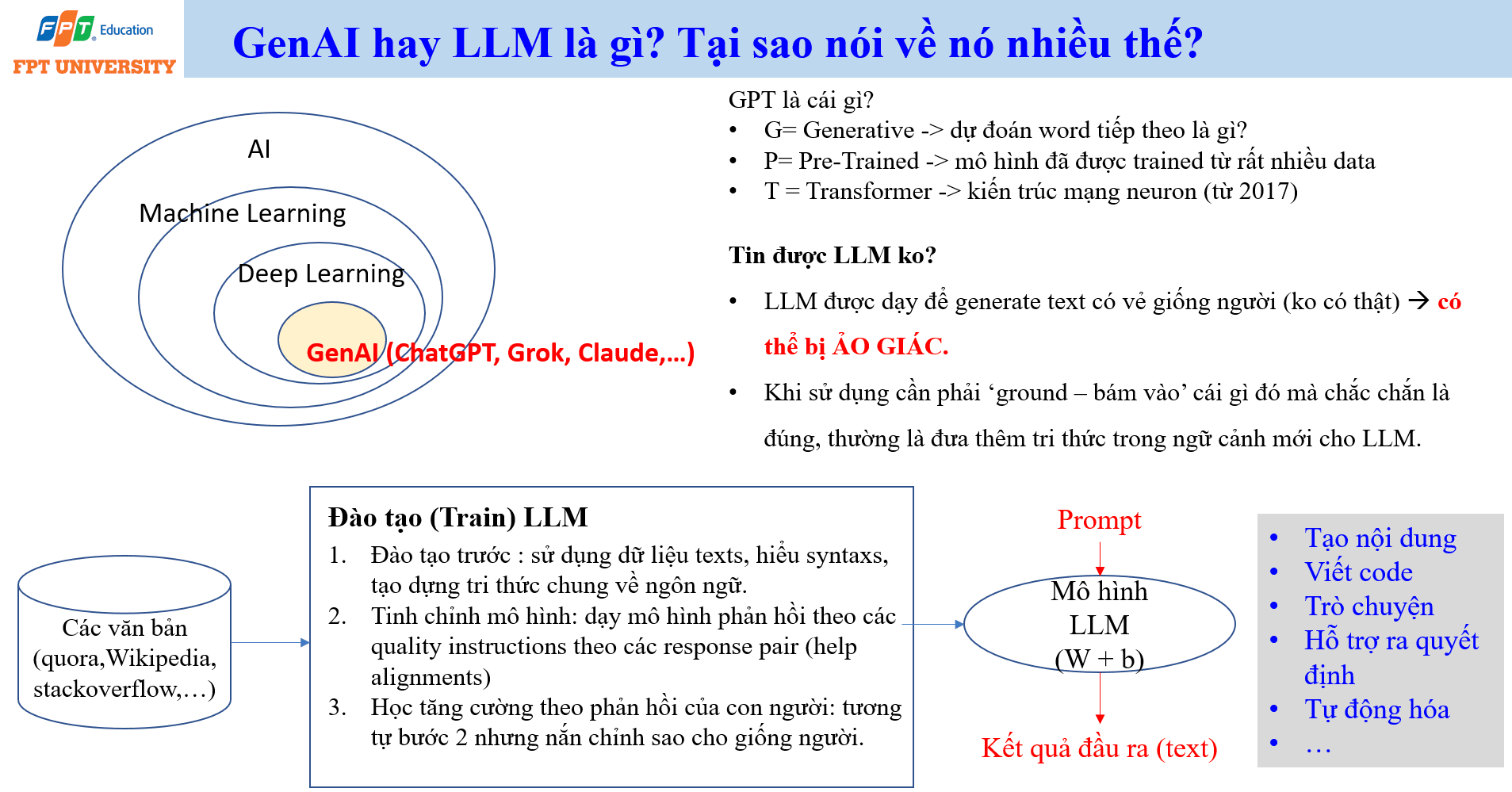
Generative AI và Large Language Model
Trí tuệ nhân tạo tạo sinh (Generative AI) là nhóm AI có khả năng tạo nội dung mới dựa trên đầu vào. Nội dung có thể là văn bản, mã nguồn, hình ảnh, âm thanh, video hoặc dữ liệu đa phương thức. Trong số các hệ thống Generative AI hiện nay, mô hình ngôn ngữ lớn (Large Language Model) tạo ra tác động xã hội rất rõ vì người dùng có thể tương tác bằng ngôn ngữ tự nhiên. ChatGPT, Grok, Claude và nhiều hệ thống tương tự thuộc nhóm này.
GPT là viết tắt của Generative Pre Trained Transformer. Generative nghĩa là mô hình có khả năng sinh nội dung, về bản chất là dự đoán đơn vị tiếp theo trong chuỗi dựa trên ngữ cảnh. Pre Trained nghĩa là mô hình đã được đào tạo trước trên lượng lớn văn bản. Transformer là kiến trúc mạng neuron ra đời từ năm 2017, giúp mô hình xử lý quan hệ ngữ cảnh trong chuỗi hiệu quả hơn các kiến trúc trước đó.
Quy trình hình thành LLM thường gồm nhiều giai đoạn. Giai đoạn đào tạo trước sử dụng khối lượng lớn văn bản để mô hình học cú pháp, ngữ nghĩa, tri thức chung và mẫu ngôn ngữ. Giai đoạn tinh chỉnh mô hình dạy mô hình phản hồi theo chỉ dẫn và tiêu chuẩn chất lượng mong muốn. Giai đoạn học tăng cường theo phản hồi con người (Reinforcement Learning from Human Feedback) tiếp tục điều chỉnh mô hình để phản hồi hữu ích hơn, an toàn hơn và gần với kỳ vọng của con người hơn.
LLM có thể tạo nội dung, viết code, trò chuyện, hỗ trợ ra quyết định và tự động hóa một số công việc tri thức. Tuy nhiên, LLM không được dạy để luôn nói sự thật theo nghĩa kiểm chứng độc lập. Nó được đào tạo để sinh văn bản có vẻ phù hợp với ngữ cảnh. Vì vậy, LLM có thể tạo ra ảo giác (hallucination), tức là nội dung nghe hợp lý nhưng sai sự thật. Khi sử dụng LLM, người dùng cần bám vào nguồn tri thức đáng tin cậy, dữ liệu nội bộ đã kiểm chứng hoặc tài liệu được cung cấp trong ngữ cảnh. Đây là lý do các kỹ thuật grounding và RAG trở nên quan trọng.
Các hướng tiếp cận khai thác LLM
LLM có thể được khai thác theo nhiều hướng khác nhau. Hướng đầu tiên là kỹ thuật prompting. Prompting là cách thiết kế chỉ dẫn đầu vào để hướng dẫn mô hình tạo ra đầu ra mong muốn. Người dùng có thể dùng few shot prompting để cung cấp vài ví dụ, chain of thought để yêu cầu mô hình phân rã suy luận, self consistency để so sánh nhiều kết quả, hoặc Socratic prompting để dẫn dắt mô hình bằng chuỗi câu hỏi. Prompting có ưu điểm là nhanh, không cần huấn luyện lại mô hình, nhưng phụ thuộc nhiều vào kỹ năng người dùng và giới hạn ngữ cảnh của mô hình.
Hướng thứ hai là tích hợp công cụ và tri thức bên ngoài. Retrieval Augmented Generation là phương pháp phổ biến. Thay vì yêu cầu LLM trả lời chỉ dựa trên tri thức đã học trong quá trình pre training, hệ thống truy xuất thông tin từ cơ sở dữ liệu, kho tài liệu hoặc hệ thống nghiệp vụ rồi đưa phần tri thức liên quan vào ngữ cảnh. Cách này giúp giảm hallucination, tăng tính cập nhật và cho phép mô hình trả lời dựa trên dữ liệu của tổ chức. Ngoài RAG, LLM cũng có thể được kết nối với công cụ tính toán, API, cơ sở dữ liệu hoặc hệ thống tác vụ.
Hướng thứ ba là tinh chỉnh mô hình (fine tuning). Fine tuning điều chỉnh LLM cho nhiệm vụ cụ thể bằng cách huấn luyện thêm trên dữ liệu có nhãn hoặc dữ liệu chỉ dẫn. Instruction tuning giúp mô hình tuân theo chỉ dẫn tốt hơn. Supervised fine tuning huấn luyện trên cặp đầu vào và đầu ra mong muốn. Reinforcement Learning from Human Feedback dùng phản hồi con người để tối ưu hành vi phản hồi. Fine tuning phù hợp khi tổ chức cần phong cách, miền tri thức hoặc nhiệm vụ ổn định mà prompting không đủ.
Hướng thứ tư là tối ưu hóa hiệu suất và bảo trì. Quantization giảm độ chính xác biểu diễn số để tiết kiệm bộ nhớ và tăng tốc. Model editing cập nhật tri thức cục bộ mà không cần huấn luyện lại toàn bộ. Machine unlearning cố gắng loại bỏ dữ liệu không mong muốn hoặc dữ liệu cần quên. Đây là nhóm kỹ thuật quan trọng khi LLM đi vào vận hành thật, vì tổ chức phải quan tâm đến chi phí, độ trễ, độ ổn định, cập nhật tri thức và tuân thủ dữ liệu.

Nhận thức phản biện khi sử dụng LLM
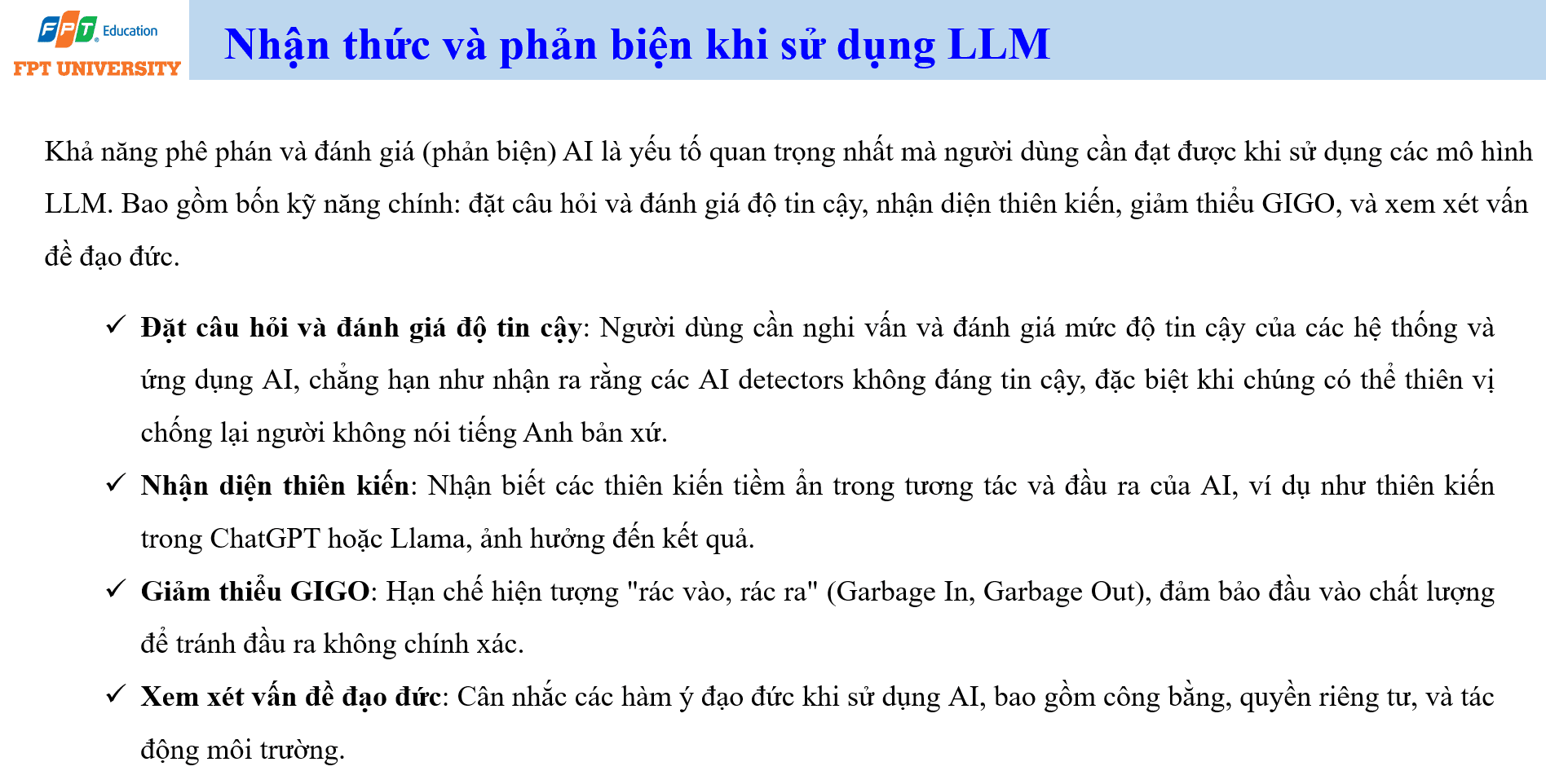
Kỹ năng quan trọng nhất khi sử dụng LLM không phải là nhập prompt dài. Kỹ năng quan trọng nhất là phản biện. Người dùng cần biết đặt câu hỏi và đánh giá độ tin cậy của đầu ra. LLM có thể trả lời trôi chảy, nhưng trôi chảy không đồng nghĩa với đúng. Khi kết quả được dùng cho ra quyết định, giảng dạy, báo cáo, tư vấn pháp lý, y tế, tài chính hoặc kỹ thuật, người dùng cần kiểm chứng bằng nguồn đáng tin cậy.
Kỹ năng thứ nhất là đánh giá độ tin cậy. Người dùng cần biết hệ thống AI nào đáng tin trong bối cảnh nào. Ví dụ, các AI detector không phải công cụ tuyệt đối đáng tin cậy. Chúng có thể thiên vị với người không nói tiếng Anh bản xứ hoặc với văn bản có phong cách quá chuẩn. Vì vậy, không nên dùng kết quả của AI detector như bằng chứng duy nhất để kết luận một người gian lận.
Kỹ năng thứ hai là nhận diện thiên kiến (bias). LLM học từ dữ liệu lớn, trong đó có thể chứa định kiến xã hội, lệch văn hóa, lệch ngôn ngữ và lệch miền tri thức. Khi mô hình phản hồi, các thiên kiến đó có thể xuất hiện dưới dạng ưu tiên một nhóm, bỏ qua một góc nhìn hoặc tạo ra kết luận không công bằng. Người dùng cần đọc kết quả với thái độ kiểm tra, đặc biệt trong các chủ đề liên quan đến con người, đánh giá năng lực, tuyển dụng, giáo dục và chính sách.
Kỹ năng thứ ba là giảm thiểu rác vào rác ra (Garbage In, Garbage Out). Nếu prompt mơ hồ, dữ liệu sai, ngữ cảnh thiếu hoặc yêu cầu không rõ, đầu ra của AI khó có chất lượng cao. Người dùng cần cung cấp mục tiêu, bối cảnh, dữ liệu, tiêu chí đánh giá và ràng buộc. Kỹ năng thứ tư là xem xét đạo đức. Sử dụng AI phải cân nhắc công bằng, quyền riêng tư, trách nhiệm và tác động xã hội. Một câu trả lời đúng về mặt kỹ thuật vẫn có thể không phù hợp nếu nó xâm phạm dữ liệu cá nhân hoặc tạo tác động bất công.
AI Agent: từ phản hồi văn bản đến hành động trong môi trường
AI Agent là hệ thống hoặc chương trình máy tính được thiết kế để thực hiện nhiệm vụ cụ thể một cách tự động và thông minh. Một agent có khả năng nhận biết môi trường, xử lý thông tin, ra quyết định và thực hiện hành động để đạt mục tiêu được đặt ra. Điểm khác biệt giữa một LLM trả lời văn bản và một AI Agent nằm ở khả năng hành động. LLM chủ yếu sinh đầu ra. AI Agent dùng đầu ra đó như một phần trong chu trình hành động.
Một AI Agent thường có các thành phần chính. Thành phần đầu vào là prompt hoặc tín hiệu từ môi trường. Thành phần xử lý đầu vào (perception) giúp agent hiểu yêu cầu và trạng thái hiện tại. Thành phần suy luận hoặc ra quyết định (reasoning and decision making) giúp agent lập kế hoạch. Thành phần bộ nhớ (memory) lưu trữ thông tin tạm thời hoặc lâu dài. Thành phần hành động (action) cho phép agent gọi API, tương tác với dịch vụ AI khác, truy cập tri thức nội bộ hoặc thực hiện thao tác trong môi trường nghiệp vụ.
Khi tích hợp LLM vào agent, LLM có thể đóng vai trò lập kế hoạch, suy luận, phân rã công việc và tạo chỉ dẫn hành động. Ví dụ, một agent hỗ trợ nghiên cứu có thể nhận yêu cầu, xác định các câu hỏi cần tìm, truy xuất tài liệu, tóm tắt kết quả, so sánh nguồn và tạo báo cáo. Một agent vận hành có thể theo dõi cảnh báo, phân loại mức độ nghiêm trọng, gọi API kiểm tra hệ thống và đề xuất hành động khắc phục.
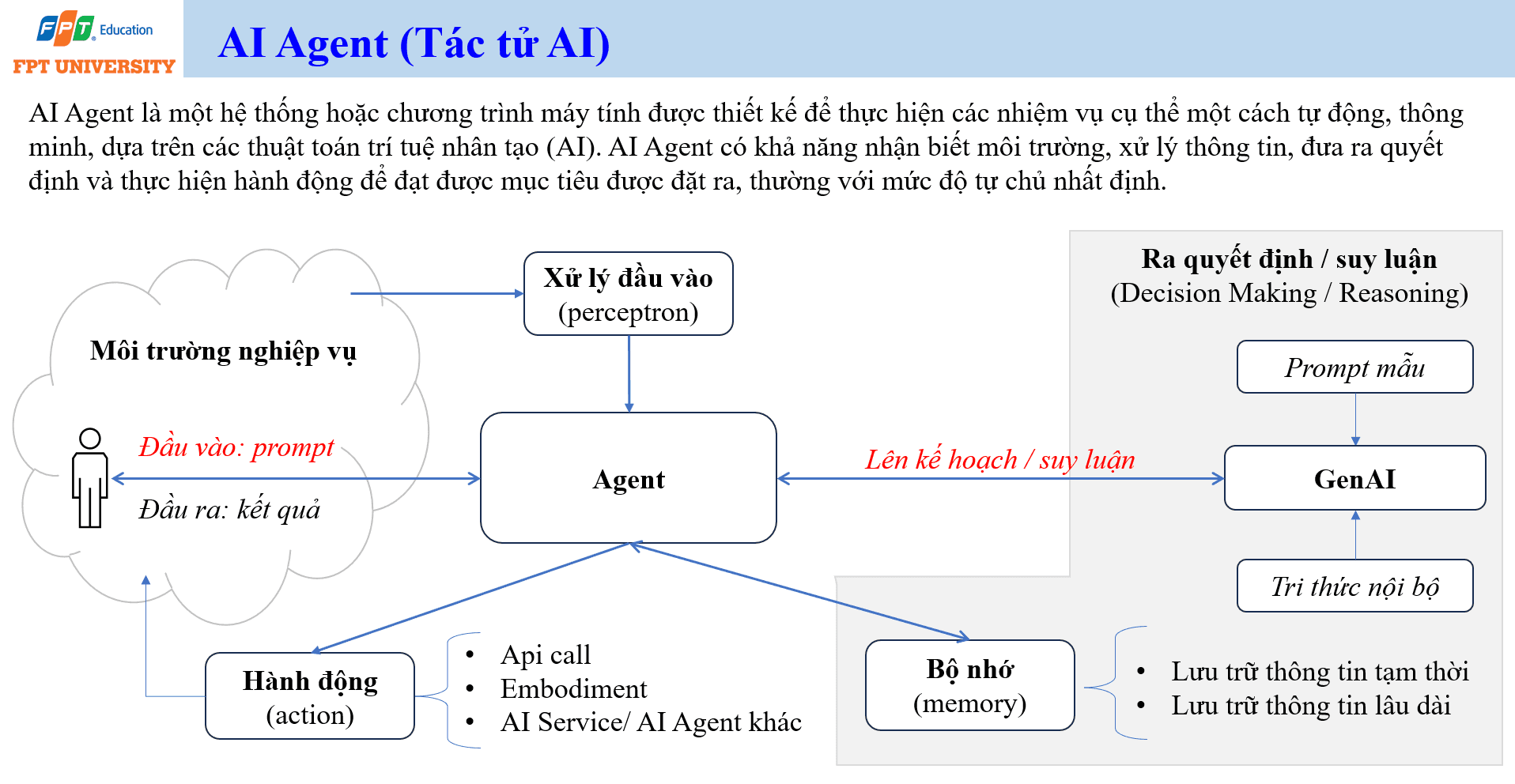
Tuy nhiên, AI Agent làm tăng yêu cầu kiểm soát. Khi một hệ thống có thể hành động, rủi ro không còn nằm ở câu trả lời sai בלבד. Rủi ro có thể là gọi nhầm API, truy cập dữ liệu không được phép, tạo thay đổi sai trong hệ thống hoặc khuếch đại hallucination thành hành động thật. Vì vậy, thiết kế AI Agent cần chú ý quyền hạn, kiểm soát truy cập, ghi log, phê duyệt của con người, giới hạn hành động và khả năng dừng hệ thống khi có bất thường.
Từ AI Agent đến Agentic AI
Agentic AI mở rộng ý tưởng AI Agent lên một mức tổ chức phức tạp hơn. Nếu một agent đơn lẻ nhận đầu vào, ra quyết định và hành động, thì Agentic AI nhấn mạnh vào sự hợp tác của nhiều agent, khả năng phân tích nhiệm vụ động, bộ nhớ bền vững, lập kế hoạch nâng cao và điều phối hệ thống. Đây là hướng tiếp cận phù hợp với các bài toán mà một mô hình hoặc một agent đơn lẻ khó xử lý hết.
Trong một hệ thống Agentic AI, có thể tồn tại nhiều agent chuyên biệt (specialized agent). Mỗi agent phụ trách một nhóm nhiệm vụ, chẳng hạn thu thập dữ liệu, phân tích dữ liệu, kiểm tra bảo mật, viết báo cáo, đánh giá chất lượng hoặc giao tiếp với người dùng. Các agent cần cộng tác với nhau thông qua một cơ chế điều phối. Nếu không có điều phối, hệ thống dễ tạo ra kết quả trùng lặp, mâu thuẫn hoặc vượt quyền.
Agentic AI cũng cần khả năng lập luận và lập kế hoạch nâng cao (advanced reasoning and planning). Một nhiệm vụ lớn cần được chia nhỏ thành các bước, xác định phụ thuộc, phân công agent, kiểm tra kết quả trung gian và điều chỉnh kế hoạch khi môi trường thay đổi. Bộ nhớ bền vững (persistent memory) giúp hệ thống giữ bối cảnh chung qua nhiều phiên làm việc, từ đó tránh lặp lại thông tin và cải thiện tính liên tục. Nhưng memory cũng tạo ra rủi ro về quyền riêng tư, dữ liệu nhạy cảm và lỗi bối cảnh nếu thông tin cũ không còn đúng.
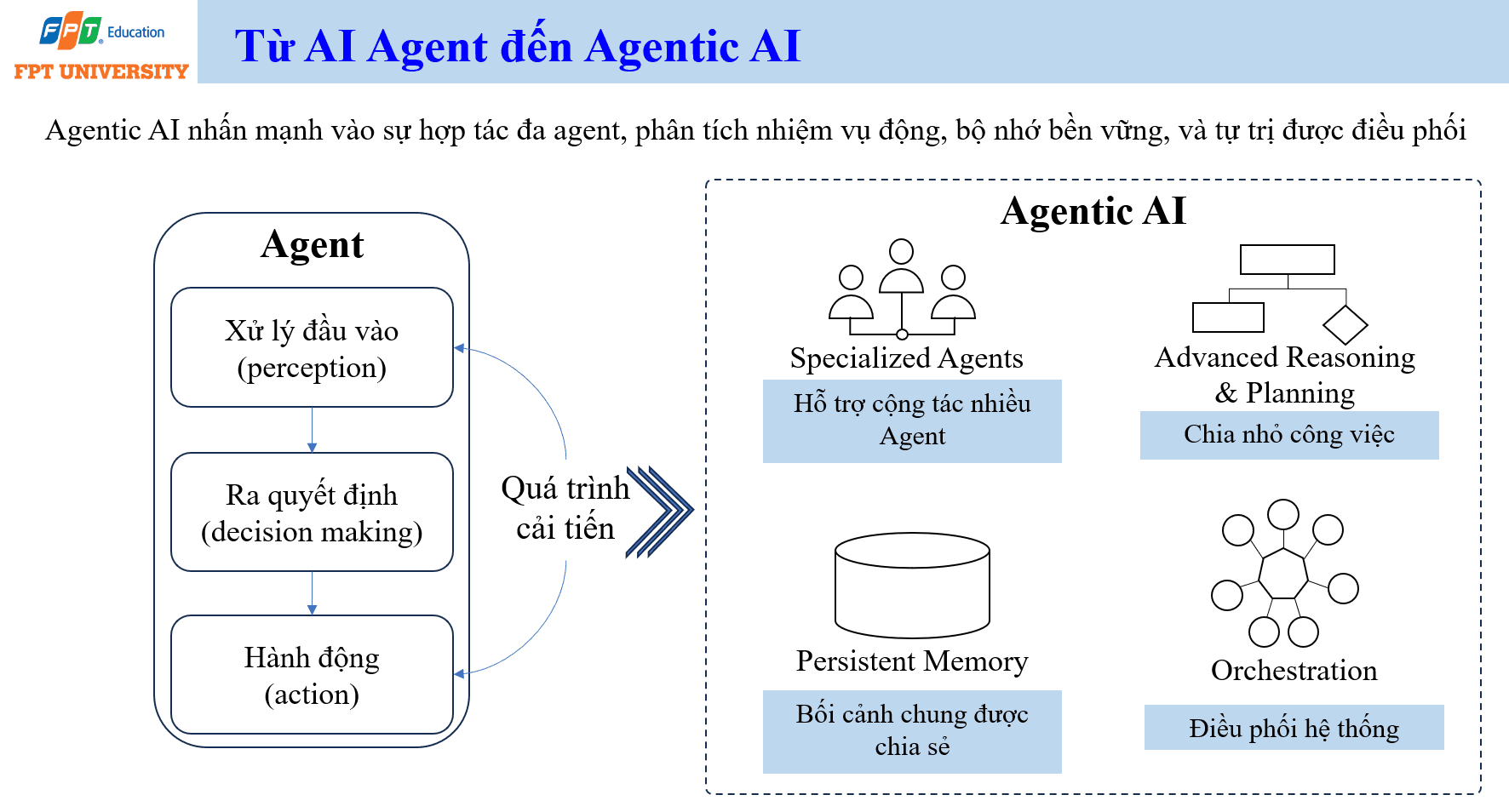
Điểm quan trọng của Agentic AI là tự chủ có điều phối. Hệ thống có thể tự động hóa nhiều bước hơn, nhưng vẫn phải nằm trong ranh giới mục tiêu, quyền hạn và kiểm soát của tổ chức. Với các nhiệm vụ nhạy cảm, cần cơ chế con người phê duyệt trước khi hành động. Với các nhiệm vụ có rủi ro thấp, hệ thống có thể tự động thực thi trong phạm vi giới hạn. Agentic AI vì vậy không chỉ là công nghệ AI. Nó là thiết kế tổ chức, quy trình, quyền hạn, trách nhiệm và kiểm soát.
Các bước triển khai Agentic Systems trong tổ chức
Triển khai hệ thống agentic không nên bắt đầu từ việc chọn công cụ. Bước đầu tiên là xác định mục tiêu rõ ràng. Tổ chức cần biết mình muốn giảm chi phí, tăng doanh thu, cải thiện hiệu quả, tự động hóa nghiên cứu, tối ưu hỗ trợ khách hàng hay cải thiện chất lượng vận hành. Nếu mục tiêu mơ hồ, agentic system dễ trở thành thử nghiệm công nghệ không tạo giá trị thật.
Bước tiếp theo là đảm bảo sáng kiến AI phù hợp với mục tiêu tổng thể. Một dự án AI chỉ có ý nghĩa khi nó hỗ trợ chiến lược lớn hơn của tổ chức. Muốn vậy, cần có sự hỗ trợ từ lãnh đạo cấp cao để phân bổ nguồn lực, xử lý thay đổi tổ chức và chấp nhận quá trình thử nghiệm. AI có thể làm thay đổi quy trình và vai trò công việc, vì vậy thiếu hỗ trợ lãnh đạo sẽ làm dự án dễ dừng ở mức thử nghiệm nhỏ.
Tổ chức nên bắt đầu với các case study có tác động cao nhưng phạm vi kiểm soát được. Một pilot đa agent cho tự động hóa nhiệm vụ có thể giúp kiểm tra khả năng thực tế trước khi mở rộng. Trong giai đoạn này, cần tư vấn chuyên gia, đánh giá năng lực IT, lựa chọn nền tảng thương mại hoặc mã nguồn mở, kiểm tra dữ liệu sẵn sàng và chuẩn bị nhân lực. Human in the loop nên được thiết kế ngay từ đầu để con người có thể kiểm tra, phê duyệt và can thiệp.
Sau pilot, tổ chức cần đo lường thành công bằng KPI, theo dõi hiệu suất và thu thập phản hồi. Hệ thống phải được lặp lại và cải thiện. Các vấn đề như hallucination có thể được giảm bằng RAG, kiểm chứng nguồn và giới hạn hành động. Khi pilot thành công, tổ chức mới mở rộng dần, đào tạo người dùng, thiết kế lớp điều phối, quản lý rủi ro và tối ưu hóa liên tục. Mở rộng quy mô không phải là nhân bản công cụ. Đó là quá trình chuẩn hóa dữ liệu, quy trình, bảo mật, kiểm soát và năng lực vận hành.

Phần 3: Những khía cạnh cần quan tâm bên cạnh yếu tố công nghệ
Những thách thức cản trở triển khai AI toàn diện
Triển khai AI toàn diện thường gặp nhiều rào cản ngoài vấn đề thuật toán. Thách thức đầu tiên là thiếu đầu tư và nguồn lực tài chính. AI cần phần cứng, phần mềm, dữ liệu, nhân sự và đào tạo. Với nhiều tổ chức, chi phí ban đầu khiến AI bị xem như công nghệ xa xỉ. Nếu đầu tư công cho nghiên cứu khoa học và công nghệ còn thấp, khả năng xây dựng năng lực AI nội sinh sẽ bị hạn chế.
Thách thức thứ hai là hạ tầng kỹ thuật số và hạ tầng tính toán yếu. AI cần dữ liệu được lưu trữ, chia sẻ và xử lý hiệu quả. Nếu dữ liệu phân tán, thiếu chuẩn, khó truy cập hoặc không có chiến lược dữ liệu mở, mô hình AI khó đạt chất lượng. Hạ tầng tính toán yếu cũng làm hạn chế khả năng training, thử nghiệm và triển khai các mô hình lớn. Nếu chính phủ điện tử và hệ thống số hóa ngành chưa mạnh, AI trong nông nghiệp, y tế hoặc hành chính công sẽ gặp khó.
Thách thức thứ ba là thiếu hụt nhân lực chuyên môn. AI cần nhà khoa học dữ liệu, kỹ sư Machine Learning, chuyên gia hạ tầng, chuyên gia bảo mật, chuyên gia pháp lý, nhà quản lý sản phẩm và người hiểu nghiệp vụ. Nếu lực lượng lao động có kỹ năng thấp, tự động hóa có thể thay thế một phần công việc mà không tạo ra năng lực mới tương ứng. Tình trạng chảy máu chất xám làm vấn đề nghiêm trọng hơn vì chuyên gia có xu hướng di chuyển sang nơi có điều kiện nghiên cứu và thu nhập tốt hơn.
Thách thức thứ tư là khung chính sách và quy định chưa hoàn thiện. AI tạo ra câu hỏi về trách nhiệm, bảo vệ dữ liệu, đạo đức và an toàn. Nếu khung pháp lý thiếu rõ ràng, tổ chức ngại triển khai hoặc triển khai thiếu kiểm soát. Thách thức cuối cùng là rủi ro xã hội. AI có thể gây mất việc làm, tăng bất bình đẳng, vi phạm quyền riêng tư và làm tổ chức phụ thuộc vào công nghệ nước ngoài. Vì vậy, triển khai AI toàn diện cần chiến lược, hạ tầng, nhân lực, chính sách và quản trị rủi ro đồng thời.

AI, dữ liệu lớn và hệ thống hỗ trợ ra quyết định
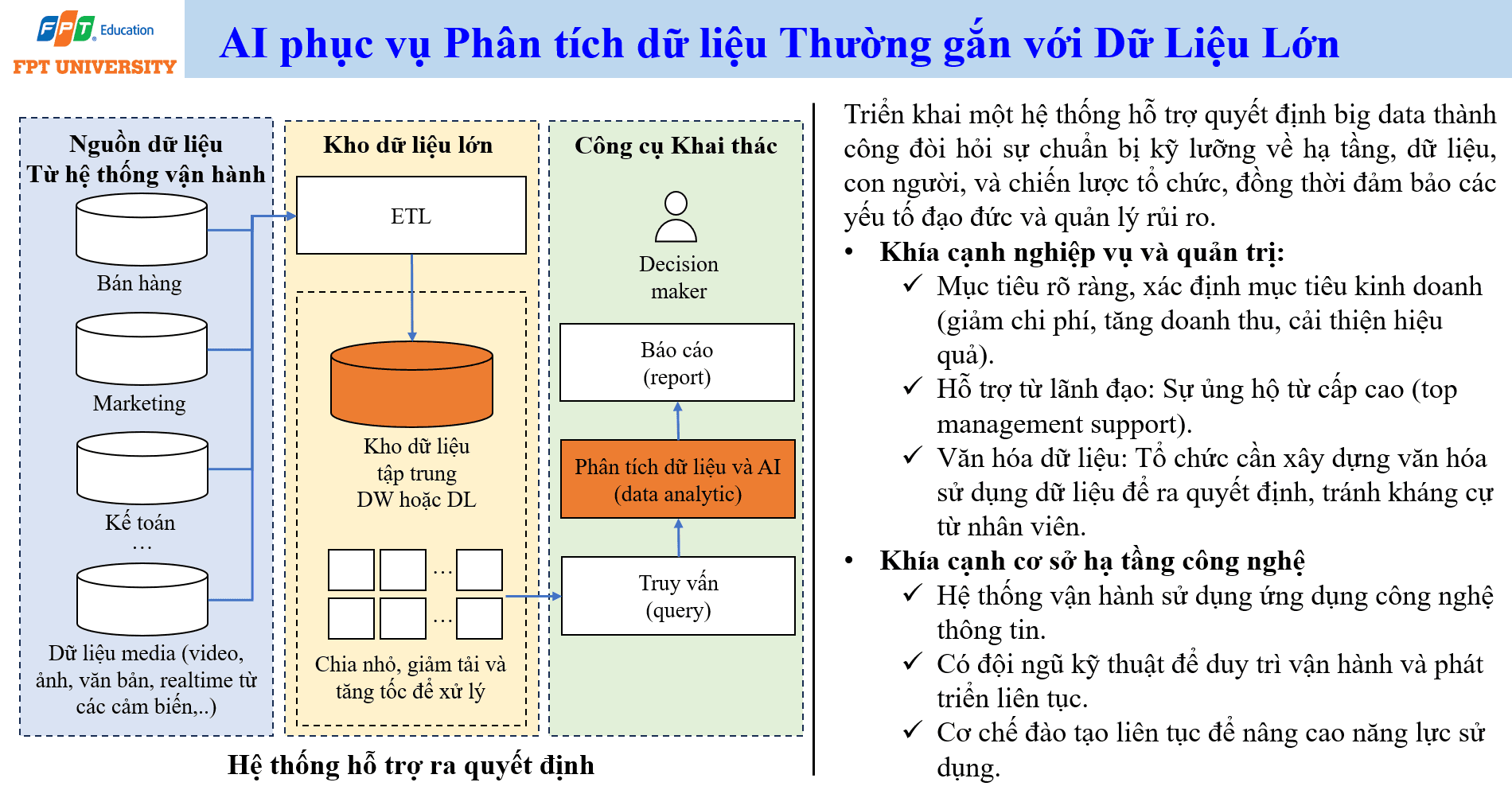
AI phục vụ phân tích dữ liệu thường gắn với dữ liệu lớn (Big Data). Dữ liệu đến từ hệ thống vận hành như bán hàng, marketing, kế toán, chăm sóc khách hàng và nhiều bộ phận khác. Ngoài dữ liệu có cấu trúc, tổ chức còn có dữ liệu media như video, ảnh, văn bản và dữ liệu thời gian thực từ cảm biến. Để AI tạo giá trị, các nguồn dữ liệu này cần được đưa vào quy trình xử lý, làm sạch, tích hợp và khai thác.
Một kiến trúc phổ biến gồm các nguồn dữ liệu, quá trình trích xuất chuyển đổi nạp (Extract Transform Load), kho dữ liệu tập trung như kho dữ liệu (Data Warehouse) hoặc hồ dữ liệu (Data Lake), công cụ khai thác, lớp truy vấn, phân tích dữ liệu và báo cáo. Khi dữ liệu quá lớn, hệ thống cần chia nhỏ, giảm tải và tăng tốc xử lý. Mục tiêu cuối cùng là cung cấp thông tin cho người ra quyết định (decision maker), không chỉ tạo ra biểu đồ đẹp.
Triển khai hệ thống hỗ trợ quyết định dựa trên Big Data và AI đòi hỏi chuẩn bị về nghiệp vụ và quản trị. Tổ chức phải xác định mục tiêu kinh doanh rõ ràng, chẳng hạn giảm chi phí, tăng doanh thu hoặc cải thiện hiệu quả. Cần có hỗ trợ từ lãnh đạo cấp cao. Cần xây dựng văn hóa dữ liệu, trong đó nhân viên dùng dữ liệu để ra quyết định thay vì chỉ dựa vào cảm tính. Nếu văn hóa dữ liệu yếu, báo cáo và mô hình AI có thể bị bỏ qua hoặc bị dùng sai.
Về hạ tầng công nghệ, hệ thống vận hành phải được số hóa đủ tốt. Tổ chức cần đội ngũ kỹ thuật để duy trì vận hành và phát triển liên tục. Cơ chế đào tạo cũng rất quan trọng vì AI và Big Data không chỉ dành cho bộ phận IT. Người dùng nghiệp vụ cần hiểu dữ liệu, hiểu báo cáo, biết đặt câu hỏi và biết phản biện kết quả phân tích. Một hệ thống AI hỗ trợ quyết định chỉ thành công khi dữ liệu, con người, quy trình và hạ tầng cùng được chuẩn bị.
Đạo đức trong AI
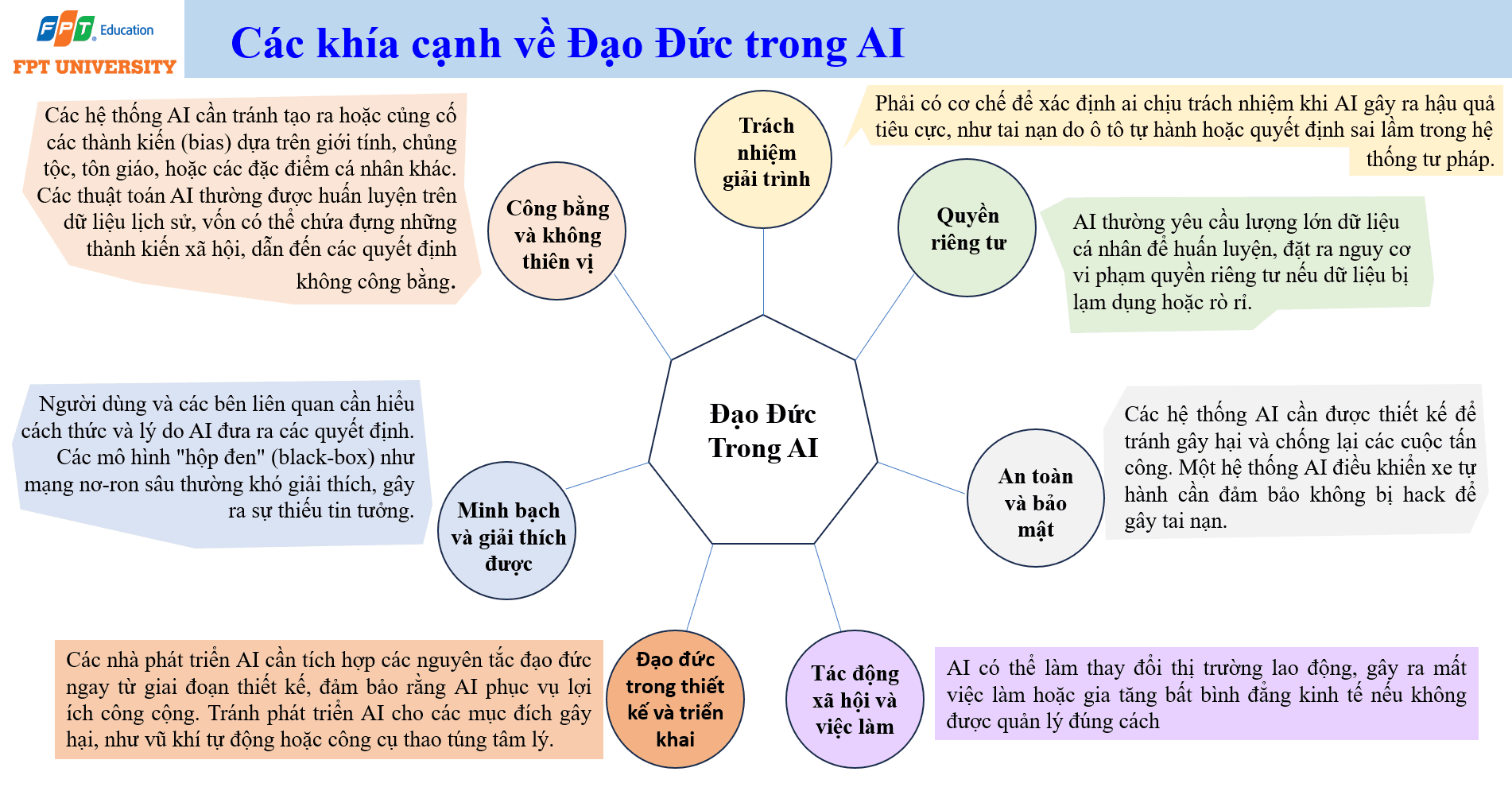
Đạo đức trong AI không phải là phần bổ sung sau khi hệ thống đã hoàn thành. Nó cần được tích hợp từ giai đoạn thiết kế và triển khai. Một hệ thống AI có thể rất chính xác về mặt kỹ thuật nhưng vẫn gây hại nếu nó thiên vị, thiếu minh bạch, xâm phạm quyền riêng tư hoặc không có cơ chế trách nhiệm. Vì vậy, đạo đức AI phải được xem như một yêu cầu thiết kế.
Khía cạnh đầu tiên là công bằng và không thiên vị. Mô hình AI thường được huấn luyện trên dữ liệu lịch sử. Nếu dữ liệu lịch sử chứa thành kiến xã hội, mô hình có thể học và củng cố thành kiến đó. Trong tuyển dụng, nếu dữ liệu quá khứ ưu ái một nhóm giới tính hoặc dân tộc, mô hình có thể loại bỏ ứng viên đủ tiêu chuẩn từ nhóm khác. Giải pháp gồm giảm thiên vị dữ liệu (data debiasing), dùng thuật toán có nhận thức về công bằng (fairness aware algorithm) và kiểm tra định kỳ tính công bằng của mô hình.
Khía cạnh thứ hai là minh bạch và giải thích được. Người dùng và bên liên quan cần hiểu vì sao AI đưa ra quyết định. Các mô hình hộp đen như mạng neuron sâu có thể khó giải thích, dẫn đến thiếu tin tưởng. Trong các lĩnh vực nhạy cảm như y tế, tài chính, giáo dục và tư pháp, việc giải thích quyết định là yêu cầu quan trọng. Khía cạnh thứ ba là trách nhiệm giải trình. Cần xác định ai chịu trách nhiệm khi AI gây hậu quả tiêu cực. Trách nhiệm có thể liên quan đến nhà phát triển, đơn vị triển khai, người vận hành, nhà cung cấp dữ liệu hoặc người phê duyệt quyết định.
Khía cạnh thứ tư là quyền riêng tư. AI thường yêu cầu lượng lớn dữ liệu cá nhân, nên nguy cơ lạm dụng hoặc rò rỉ dữ liệu rất cao. Khía cạnh thứ năm là an toàn và bảo mật. Hệ thống AI cần chống lại tấn công, thao túng dữ liệu, prompt injection, đánh cắp mô hình và truy cập trái phép. Khía cạnh cuối cùng là tác động xã hội và việc làm. AI có thể tạo năng suất, nhưng cũng có thể gây mất việc hoặc tăng bất bình đẳng nếu không được quản lý đúng cách.
Tự xây dựng AI hay sử dụng AI như một dịch vụ
Khi triển khai AI, tổ chức thường đứng trước lựa chọn tự phát triển hệ thống AI hoặc sử dụng AI như một dịch vụ (AI as a Service). AI as a Service có chi phí ban đầu thấp, thường dựa trên mô hình trả tiền theo mức sử dụng. Thời gian triển khai nhanh, có thể chỉ mất vài tuần nếu yêu cầu không quá đặc thù. Yêu cầu kỹ thuật ban đầu cũng thấp hơn vì nhà cung cấp chịu trách nhiệm phần lớn về hạ tầng, mô hình và bảo trì.
Nhược điểm của AI as a Service là khả năng tùy chỉnh hạn chế và thường mang tính hộp đen (black box). Tổ chức không kiểm soát đầy đủ cách mô hình được huấn luyện, dữ liệu được xử lý và kết quả được tạo ra. Vấn đề bảo mật dữ liệu rất đáng chú ý vì dữ liệu có thể được gửi đến máy chủ nhà cung cấp. Nếu dữ liệu là dữ liệu y tế, tài chính, thông tin cá nhân hoặc dữ liệu quốc gia, rủi ro rò rỉ, truy cập trái phép hoặc sử dụng lại dữ liệu để huấn luyện mô hình cần được kiểm soát bằng hợp đồng, kỹ thuật và chính sách.
Tự phát triển AI có chi phí ban đầu cao hơn. Tổ chức phải đầu tư hạ tầng, nhân sự, dữ liệu, bảo mật và vận hành. Thời gian triển khai cũng lâu hơn. Tuy nhiên, đổi lại là khả năng tùy chỉnh cao, kiểm soát dữ liệu tốt hơn và phù hợp với các tổ chức lớn hoặc ngành nhạy cảm như chính phủ, y tế, tài chính. Khi dữ liệu được lưu trữ và xử lý nội bộ, nguy cơ rò rỉ ra bên ngoài có thể giảm, nhưng tổ chức vẫn phải đối mặt với tấn công nội bộ, cấu hình sai và thiếu năng lực bảo mật.
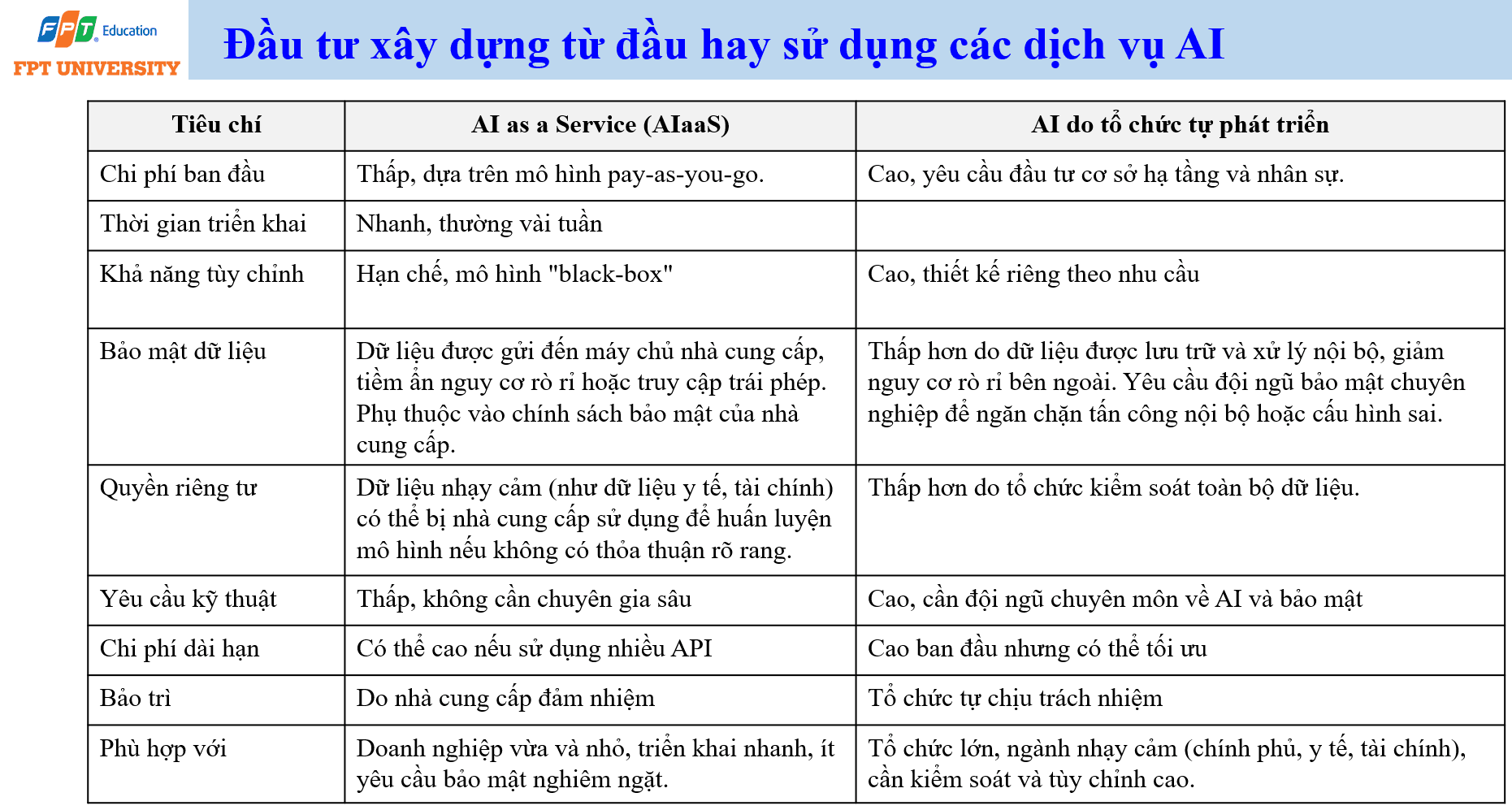
Không có lựa chọn đúng cho mọi tổ chức. Doanh nghiệp vừa và nhỏ, ít yêu cầu bảo mật nghiêm ngặt, cần triển khai nhanh có thể bắt đầu với AI as a Service. Tổ chức lớn, có dữ liệu nhạy cảm, cần kiểm soát và tùy chỉnh cao nên cân nhắc tự phát triển hoặc triển khai mô hình lai. Điều quan trọng là quyết định phải dựa trên chi phí, thời gian, bảo mật, quyền riêng tư, năng lực kỹ thuật, chi phí dài hạn và mức độ phù hợp với mục tiêu chiến lược.
Các tiêu chí đánh giá một hệ thống AI
Một hệ thống AI không nên được đánh giá chỉ bằng cảm nhận người dùng. Cần có các tiêu chí định lượng và định tính rõ ràng. Nội dung bài giảng nêu năm nhóm tiêu chí: chi phí (cost), độ trễ (latency), độ chính xác (accuracy), độ ổn định (stability) và an toàn (security). Năm tiêu chí này giúp tổ chức nhìn AI như một hệ thống vận hành thật, không chỉ như một mô hình thử nghiệm.
Chi phí cho một lần thực thi phụ thuộc vào số lượng token đầu vào, số lượng token đầu ra và đơn giá tương ứng của từng loại token. Có thể biểu diễn đơn giản như sau: Cost = InputToken x InputPrice + OutputToken x OutputPrice. Với hệ thống dùng API LLM, chi phí có thể tăng nhanh khi số người dùng, số tài liệu và độ dài ngữ cảnh tăng. Vì vậy, tối ưu prompt, dùng cache, chọn mô hình phù hợp và giới hạn ngữ cảnh là các biện pháp quan trọng.
Độ trễ là thời gian trung bình cần thiết để hệ thống hoàn thành một quy trình công việc. Nếu có n lần thực thi, latency trung bình có thể tính bằng tổng thời gian của n lần chia cho n. Với ứng dụng tương tác trực tiếp, latency ảnh hưởng mạnh đến trải nghiệm người dùng. Một mô hình rất chính xác nhưng phản hồi quá chậm có thể không phù hợp trong quy trình vận hành.
Độ chính xác phản ánh tỷ lệ công việc được hoàn thành thành công so với tổng số công việc được thực hiện. Accuracy = SuccessfulTask / TotalTask x 100 phần trăm. Độ ổn định đo mức nhất quán của hiệu suất hoặc kết quả qua nhiều lần chạy với cùng dữ liệu đầu vào và cùng cấu hình. An toàn đo tỷ lệ phản hồi không gây hại trên tổng số prompt kiểm thử tấn công hoặc prompt tiêm nhiễm. Với hệ thống AI hiện đại, security không chỉ là bảo mật hạ tầng. Nó còn gồm chống prompt injection, bảo vệ dữ liệu, lọc nội dung độc hại và kiểm soát hành động của agent.

Kết luận: dùng AI như một năng lực tổ chức có kiểm soát
AI đang trở thành một năng lực cốt lõi trong xã hội số. Nó nằm ở trung tâm của cách mạng công nghiệp lần thứ tư, gắn chặt với chuyển đổi số và dữ liệu lớn. Nhưng AI không phải là mục tiêu tự thân. Mục tiêu của AI là giúp tổ chức tạo ra sản phẩm mới, dịch vụ mới, quy trình tốt hơn và giá trị xã hội lớn hơn. Khi AI giúp khách hàng được phục vụ tốt hơn, nhân viên làm việc hiệu quả hơn, doanh nghiệp vận hành thông minh hơn và xã hội sử dụng tài nguyên hợp lý hơn, AI mới thật sự tạo giá trị.
Để đạt được điều đó, tổ chức cần hiểu AI ở nhiều tầng. Ở tầng khái niệm, cần phân biệt AI, Machine Learning, Deep Learning, Generative AI, LLM, AI Agent và Agentic AI. Ở tầng kỹ thuật, cần hiểu dữ liệu, mô hình, training, prediction, parameter, hyperparameter, GPU, RAG và fine tuning. Ở tầng vận hành, cần hiểu chi phí, độ trễ, độ chính xác, độ ổn định, bảo mật và tích hợp với hệ thống thông tin. Ở tầng tổ chức, cần có AI Literacy, chiến lược dữ liệu, hỗ trợ lãnh đạo, nhân lực và văn hóa dùng dữ liệu để ra quyết định.
Quan trọng hơn, AI phải được triển khai có trách nhiệm. Các vấn đề về công bằng, minh bạch, trách nhiệm giải trình, quyền riêng tư, an toàn và tác động xã hội không thể bị xem nhẹ. Một hệ thống AI mạnh nhưng thiếu kiểm soát có thể tạo ra rủi ro lớn hơn lợi ích. Một hệ thống AI đơn giản nhưng bám sát nhu cầu thật, dữ liệu đúng, quy trình rõ và có người chịu trách nhiệm có thể tạo giá trị bền vững hơn nhiều.
Vì vậy, cách tiếp cận phù hợp là xem AI như một năng lực tổ chức có kiểm soát. Tổ chức cần bắt đầu từ mục tiêu, dữ liệu và vấn đề thật. Sau đó chọn công nghệ phù hợp, triển khai thử nghiệm nhỏ, đo lường, cải tiến và mở rộng dần. AI không thay thế tư duy quản trị. AI yêu cầu tư duy quản trị tốt hơn. AI không thay thế con người có trách nhiệm. AI yêu cầu con người hiểu công cụ, biết phản biện và biết thiết kế hệ thống phục vụ lợi ích chung.