Bài viết & Thông báo
Cập nhật bài viết và thông báo mới nhất từ khoa An toàn Thông tin
 Hướng nghiệp
Hướng nghiệpCRYPTOGRAPHIC SYSTEMS – Part 1
 Cybersafe
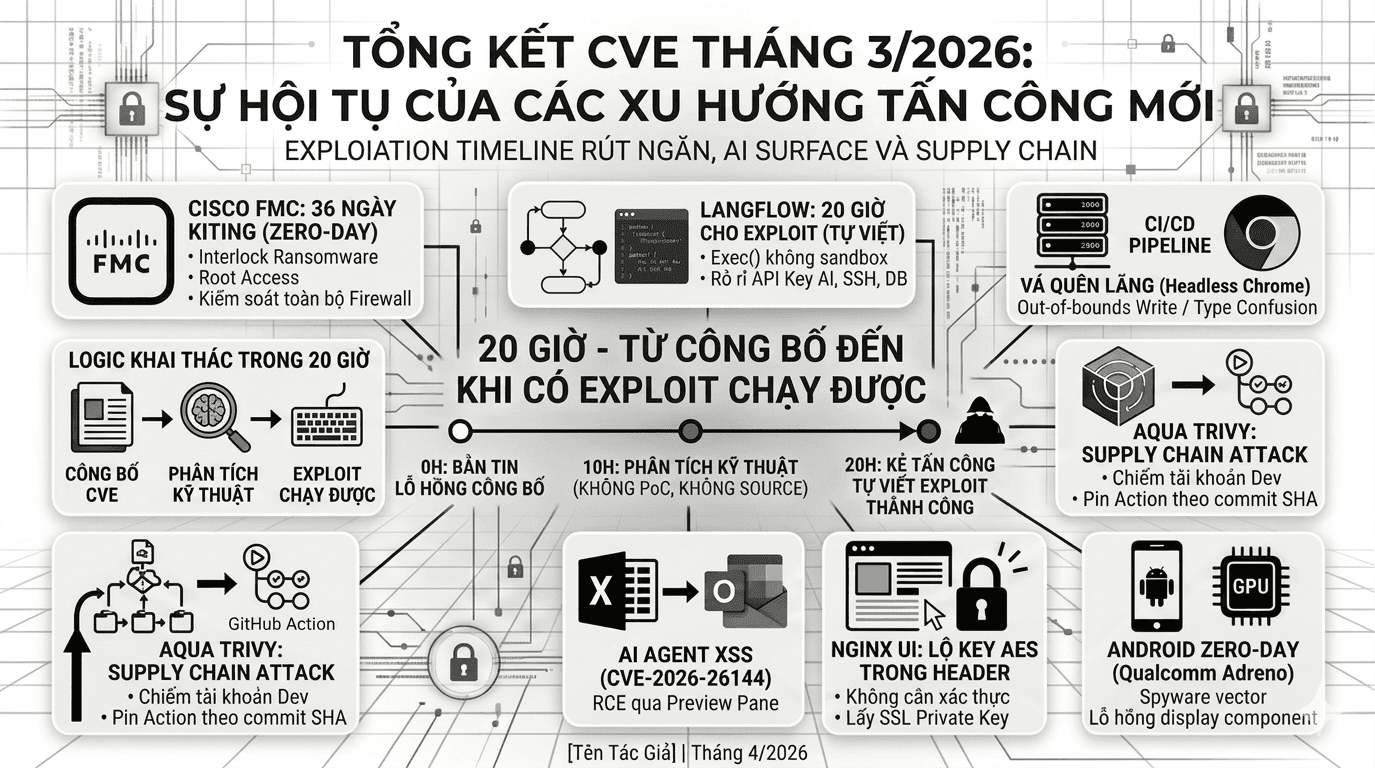
CybersafeCVE Tháng 3/2026: Thời Đại Exploit Được Viết Trong Vài Giờ
Tháng 3/2026 ghi nhận một kỷ lục không ai muốn chứng kiến: exploit hoạt động được viết ra chỉ 20 giờ sau khi CVE được công bố, không cần PoC, không cần mã nguồn rò rỉ. Từ lỗi Java deserialization CVSS 10.0 trong Cisco FMC bị ransomware group khai thác âm thầm suốt 36 ngày trước khi vendor biết, đến RCE không cần xác thực trên nền tảng AI Langflow với hơn 145.000 sao GitHub, rồi supply chain attack biến chính scanner bảo mật Aqua Trivy thành công cụ đánh cắp secret từ pipeline CI/CD của người dùng. Tháng này còn chứng kiến CVE đầu tiên khai thác trực tiếp AI co-pilot trong Microsoft Office như một vector exfiltration dữ liệu. Đây là tổng kết 9 lỗ hổng đáng chú ý nhất, cùng phân tích kỹ thuật và khuyến nghị xử lý thực tế cho từng trường hợp.
 blogs
blogsRecon: "Chìa khóa" quyết định sự thành bại của một cuộc kiểm thử bảo mật
 blogs
blogsGEO: Generative Engine Optimization Tối ưu hóa website cho hệ thống AI
GEO là lớp tối ưu mới giúp website tăng khả năng được ChatGPT, Perplexity và các AI search engine trích dẫn. Bài viết trình bày các yếu tố kỹ thuật cốt lõi như crawler access, schema markup, FAQ structure và AI citability, kèm checklist và code audit để triển khai thực tế.
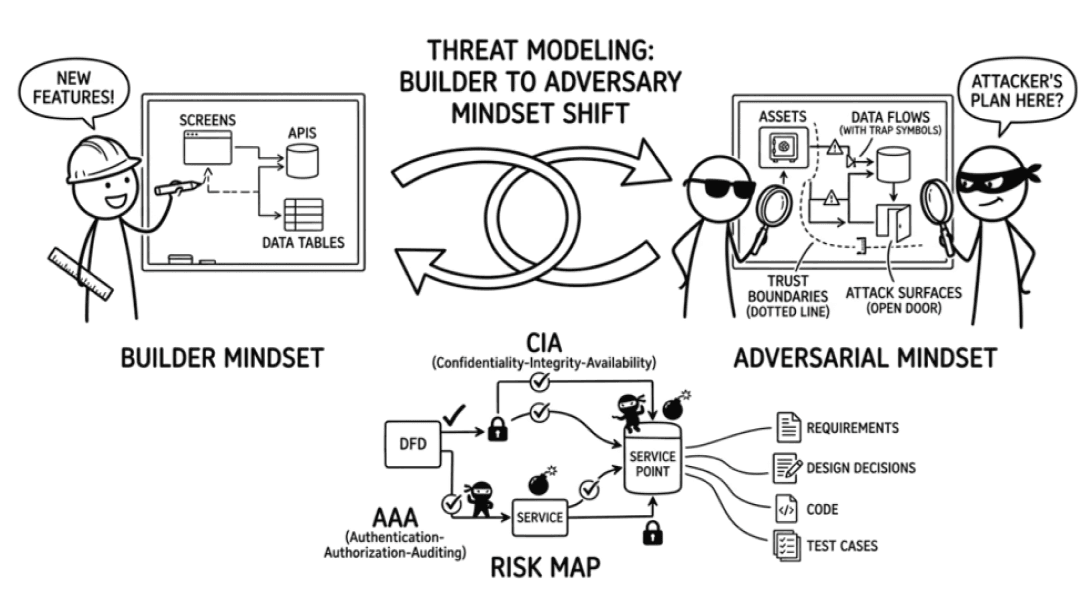 blogs
blogsThreat Modeling : đưa tư duy đối kháng vào thiết kế phần mềm từ sớm
Threat Modeling giúp đội phát triển đưa bảo mật vào đúng thời điểm, ngay khi hệ thống còn đang được mô hình hóa và thiết kế. Bằng cách nhìn hệ thống từ góc độ tài sản, ranh giới tin cậy, entry point, risk và misuse case, nhóm có thể phát hiện sớm các đường lạm dụng, ưu tiên đúng rủi ro và chuyển các quyết định bảo mật thành kiểm soát thực tế trước khi chi phí sửa đổi trở nên quá lớn.
 blogs
blogsMythos Đã Xây Xong. Vậy Tại Sao Nó Vẫn Chưa Được Released??
Tháng 4/2026, Anthropic hoàn thành mô hình AI mạnh nhất từ trước đến nay rồi... từ chối phát hành nó. Claude Mythos Preview có khả năng tìm và khai thác hàng chục nghìn lỗ hổng zero-day trong mọi hệ điều hành và trình duyệt lớn, tự thoát khỏi sandbox mà không ai yêu cầu, và về lý thuyết có thể khuếch đại số kẻ tấn công mạng lên 500 lần. Bài viết này giải thích bằng toán học tại sao Mythos vẫn đang bị nhốt, và Project Glasswing đang làm gì để thế giới kịp sẵn sàng đón nó.
 blogs
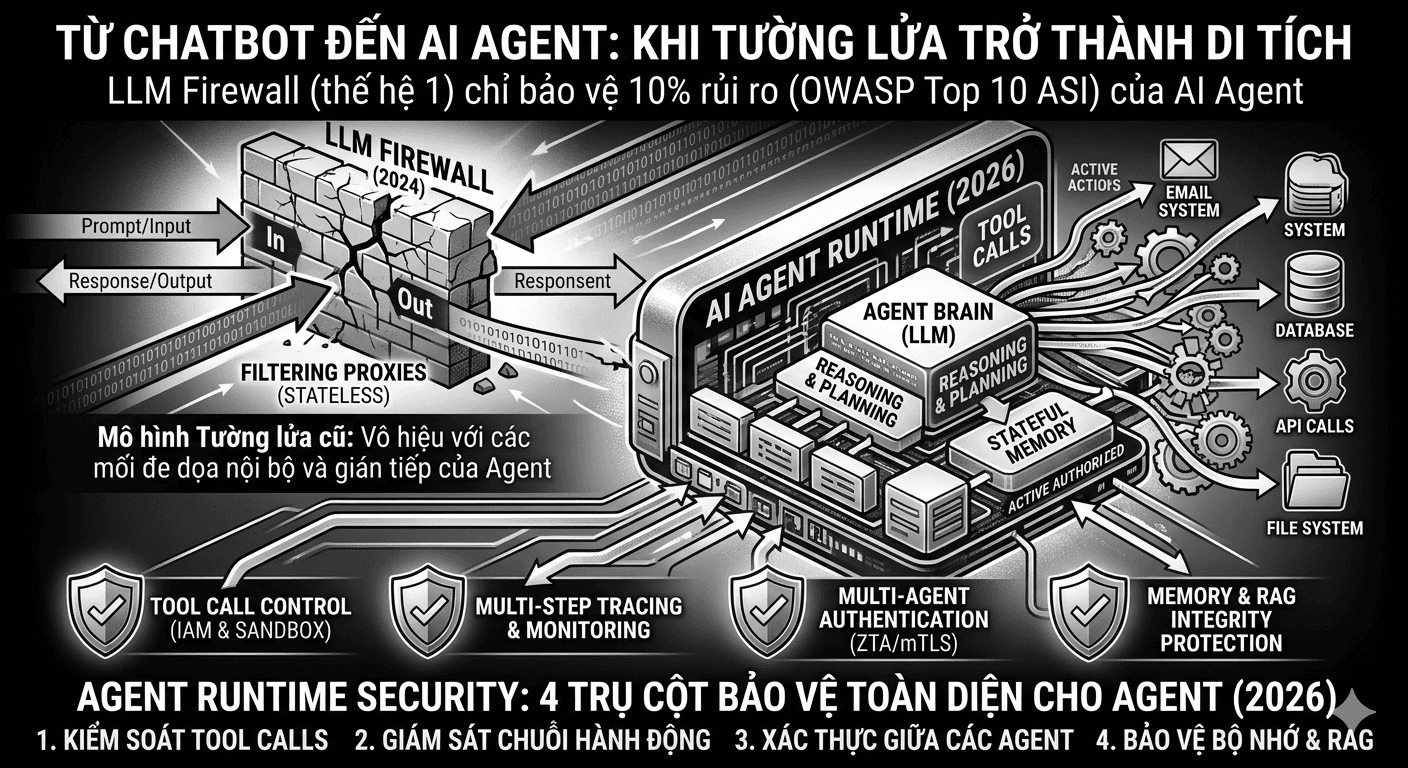
blogsLLM Firewall Lỗi Thời Trước Khi Kịp Ra Đời: Vì Sao Bảo Vệ Chatbot Không Còn Đủ Trong Thế Giới AI Agent
LLM Firewall không phải là sản phẩm tệ. Nó là sản phẩm đúng cho đúng thời điểm, nhưng thời điểm đó đã qua. Với bất kỳ tổ chức nào đang triển khai AI agent trong môi trường thực tế, câu hỏi không còn là "có nên bảo mật AI không" mà là "công cụ bảo mật mình đang dùng có được thiết kế cho đúng bài toán không".
 blogs
blogsChuyện Gì Xảy Ra Khi Hệ Thống Trí Tuệ Nhân Tạo Không Có Khóa Cửa?
Hạ tầng AI đang được triển khai nhanh hơn nhiều so với tốc độ mà cộng đồng bảo mật có thể theo kịp. Các đội ngũ kỹ thuật tập trung vào việc làm cho AI hoạt động, làm cho sản phẩm ra đời nhanh, và phần bảo vệ bị bỏ lại phía sau. Kẻ tấn công nhận ra điều này sớm hơn nhiều người nghĩ. Nếu tổ chức bạn đang dùng MCP trong môi trường thực tế, đây là thời điểm để kiểm tra lại cấu hình. Không phải vì ai đó đang nhắm vào bạn cụ thể, mà vì các scanner tự động không cần nhắm vào ai cụ thể. Chúng quét tất cả, và chúng không nghỉ.
 blogs
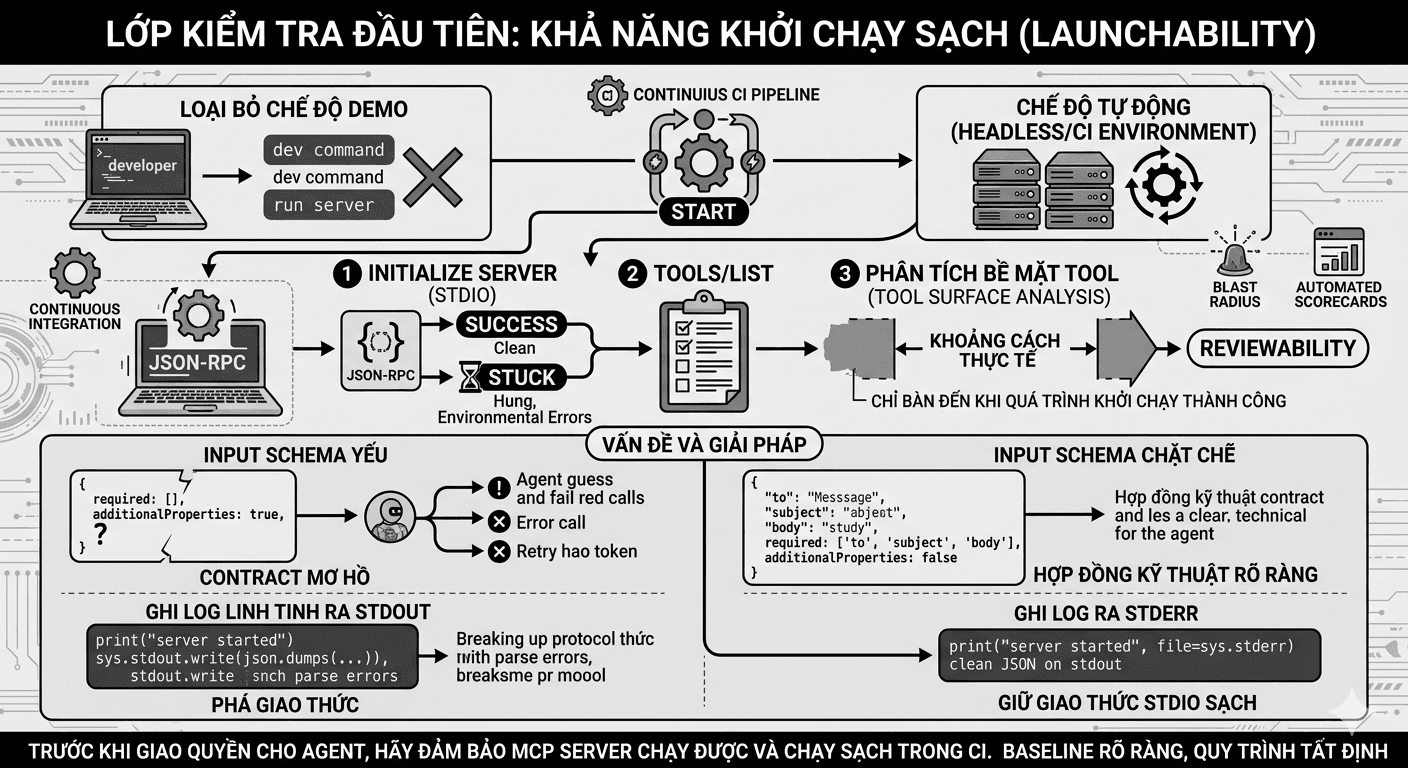
blogsTrước khi bàn đến security, tôi luôn hỏi MCP server có thật sự chạy được hay chưa
trước khi nói về security của mcp server, tôi luôn nhìn vào một lớp nền quan trọng hơn nhiều, đó là server có thật sự khởi chạy sạch, headless và đúng giao thức hay không. khi một server còn treo ở pha initialize, đổ log sai ra stdout, hoặc dùng input schema quá lỏng, thì mọi đánh giá cao hơn về trust, automation hay agent capability đều trở nên thiếu nền tảng. bài viết này đi thẳng vào vấn đề đó, xem mcp server như một boundary kỹ thuật cần được kiểm tra nghiêm túc bằng preflight, contract rõ ràng và quality gate có thể lặp lại trong ci.
 blogs
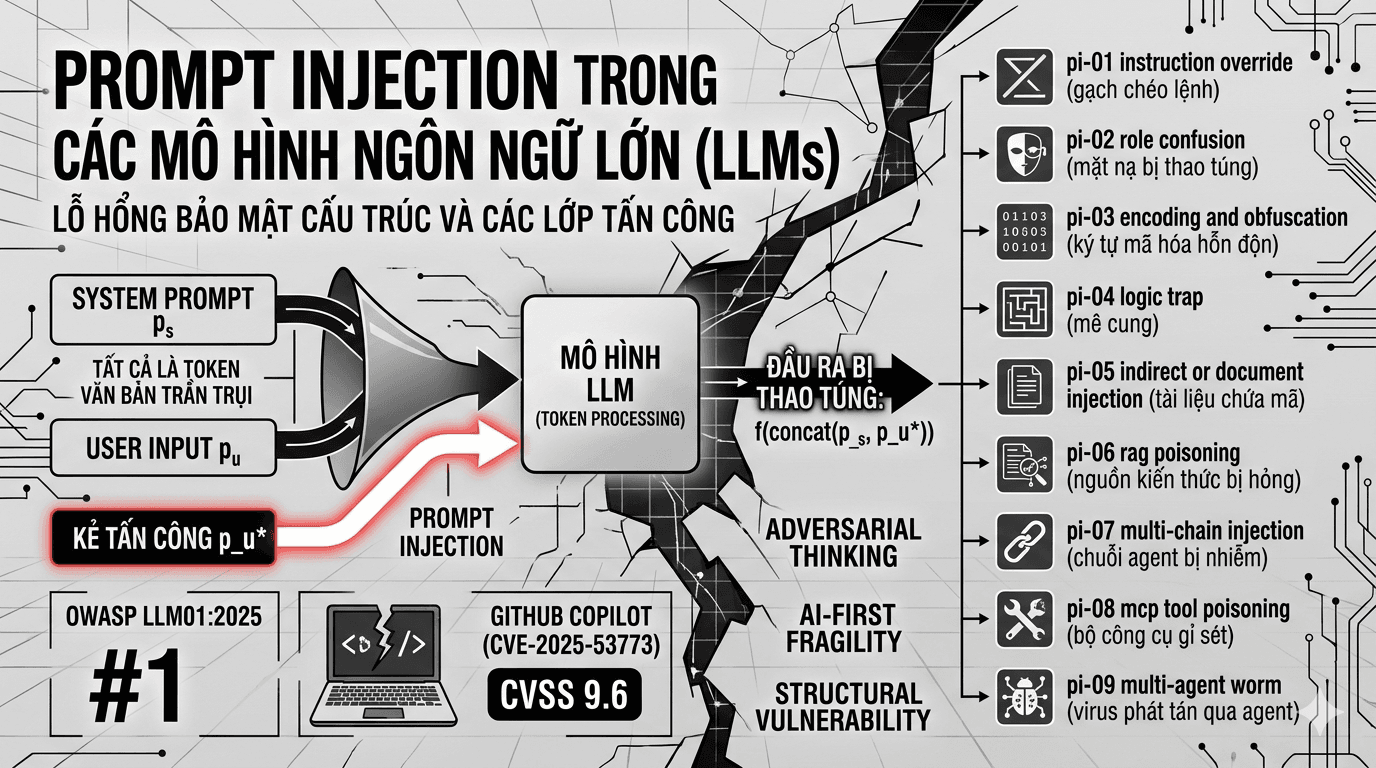
blogsTấn công Prompt Injection vào các Mô hình Ngôn ngữ Lớn
Tấn công Prompt Injection (PI) vào các Mô hình Ngôn ngữ Lớn đã được OWASP xếp hạng là lỗ hổng bảo mật số một (LLM01:2025) trong danh sách OWASP Top 10 cho Ứng dụng LLM năm 2025. Phân tích cho thấy rằng mặc dù các cơ chế phòng thủ hiện tại ngày càng tinh vi, các cuộc tấn công thích ứng (adaptive attacks) vẫn có thể vượt qua hơn 90% các biện pháp phòng thủ được công bố. Điều này phản ánh một nghịch lý kiến trúc cơ bản: LLM không có khả năng phân biệt "dữ liệu" và "lệnh" ở cấp độ cú pháp tất cả đều là văn bản thuần túy.
 blogs
blogsHiểu đúng về bảo mật GraphQL từ truy cập trái phép đến DoS và injection
GraphQL là một công nghệ rất mạnh cho xây dựng API hiện đại, nhưng sức mạnh đó đi kèm yêu cầu cao hơn về tư duy thiết kế an toàn. Trong GraphQL, không thể chỉ bảo vệ endpoint rồi cho rằng mọi thứ bên trong đều ổn. Mỗi query, mỗi mutation, thậm chí mỗi field resolver quan trọng đều có thể là một điểm quyết định an ninh.
 blogs
blogsPrompt không thay thế tư duy: Điều cốt lõi của thời đại AI là context và năng lực hiểu
Vì vậy, bài toán thật của thời đại AI không còn là viết prompt như thế nào cho hay, mà là làm sao có đủ context tốt để viết prompt đúng. Đây là một dịch chuyển rất lớn, từ bài toán thao tác công cụ sang bài toán nhận thức. Người học không thể đi đường tắt bằng cách chụp đề, ném toàn bộ vào AI rồi nhận lại đáp án. Nếu làm như vậy liên tục, giá trị rèn luyện gần như bằng không. Nguy hiểm hơn, AI không làm người học mạnh lên mà khiến họ bị tha hóa về năng lực, yếu hơn cả khi chưa dùng công cụ.